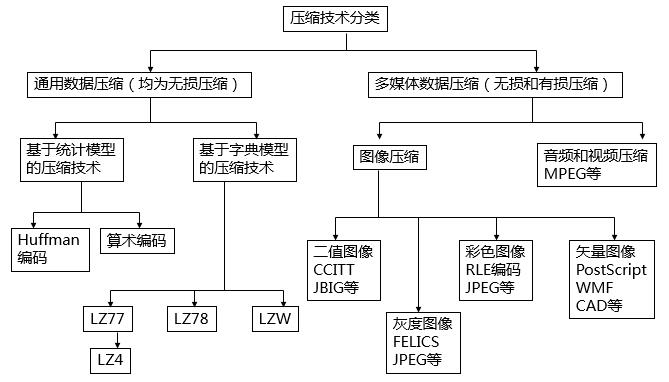
数据压缩
编辑在信号处理中,数据压缩是使用比原始表示少的比特对信息进行编码的过程。任何特定的压缩要么是有损的,要么是无损的。无损压缩通过识别和消除统计冗余来减少比特。无损压缩不会丢失任何信息。有损压缩通过删除不必要的或不太重要的信息来减少位。通常,执行数据压缩的设备称为编码器,执行逆向处理(解压缩)的设备称为解码器。
减小数据文件大小的过程通常称为数据压缩。在数据传输的上下文中,它被称为源编码;在数据存储或传输之前在数据源处完成编码。源编码不应与信道编码混淆,用于错误检测和纠正或线路编码,将数据映射到信号的手段。
压缩很有用,因为它减少了存储和传输数据所需的资源。计算资源消耗在压缩和解压过程中。数据压缩需要权衡时空复杂度。例如,视频的压缩方案可能需要昂贵的硬件来解压缩视频,以便在解压缩时足够快地进行查看,并且在观看之前完全解压缩视频的选项可能不方便或需要额外的存储空间。数据压缩方案的设计涉及各种因素之间的权衡,包括压缩程度、引入的失真量(当使用有损数据压缩时)),以及压缩和解压缩数据所需的计算资源
无损数据压缩
编辑无损数据压缩算法通常利用统计冗余来表示数据而不会丢失任何信息,因此该过程是可逆的。无损压缩是可能的,因为大多数真实世界的数据都表现出统计冗余。例如,图像可能具有在几个像素内不会改变的颜色区域;可以将数据编码为“279个红色像素”,而不是编码“红色像素、红色像素……”。这是游程编码的基本示例;有许多方案可以通过消除冗余来减小文件大小。
所述的Lempel-谢夫(LZ)压缩方法是最流行的算法的无损存储中。DEFLATE是LZ的变体,针对解压速度和压缩率进行了优化,但压缩速度可能很慢。在1980年代中期,在TerryWelch的工作之后,Lempel-Ziv-Welch(LZW)算法迅速成为大多数通用压缩系统的首选方法。LZW用于GIF图像、PKZIP等程序以及调制解调器等硬件设备。LZ方法使用基于表的压缩模型,其中表条目被替换为重复的数据字符串。对于大多数LZ方法,此表是从输入中的较早数据动态生成的。表格本身通常是霍夫曼编码的。像这样的基于语法的代码可以非常有效地压缩高度重复的输入,例如,相同或密切相关物种的生物数据集合、庞大的版本化文档集合、互联网档案等。基于语法的代码的基本任务是构建派生单个字符串的上下文无关文法。其他实用的语法压缩算法包括Sequitur和Re-Pair。
xxx大的现代无损压缩器使用概率模型,例如通过部分匹配进行预测。的变换惠勒挖洞也可以看作是统计建模的间接形式。在直接使用概率建模的进一步改进中,可以将统计估计与称为算术编码的算法耦合。算术编码是一种更现代的编码技术,它使用有限状态机的数学计算从一系列输入数据符号产生一串编码位。与其他技术(例如更为人所知的霍夫曼算法)相比,它可以实现卓越的压缩。它使用内部存储器状态来避免将单个输入符号一对一映射到使用整数位的不同表示的需要,并且仅在对整个数据符号串进行编码后才清除内部存储器.算术编码特别适用于统计变化且依赖于上下文的自适应数据压缩任务,因为它可以很容易地与输入数据概率分布的自适应模型耦合。使用算术编码的早期示例是JPEG的一个可选(但未广泛使用)功能图像编码标准。此后,它已应用于各种其他设计,包括用于视频编码的H.263、H.264/MPEG-4AVC和HEVC。
存档软件通常具有调整“字典大小”的能力,其中较大的大小在压缩和解压缩过程中需要更多的随机存取内存,但压缩能力更强,尤其是在文件内容中的重复模式时。
有损数据压缩
编辑在80年代后期,数字图像变得更加普遍,并且出现了无损图像压缩标准。在90年代初期,有损压缩方法开始得到广泛应用。在这些方案中,一些信息丢失是可以接受的,因为丢弃不重要的细节可以节省存储空间。在保留信息和减小大小之间存在相应的权衡。有损数据压缩方案是通过研究人们如何感知相关数据而设计的。例如,人眼对亮度的细微变化比对颜色的变化更敏感。JPEG图像压缩的部分工作是通过舍入不重要的信息位来实现的。许多流行的压缩格式利用了这些感知差异,包括声音的心理声学以及图像和视频的心理视觉。
大多数形式的有损压缩都基于变换编码,尤其是离散余弦变换(DCT)。它由NasirAhmed于1972年首次提出,然后他于1973年与T.Natarajan和KRRao共同开发了一种工作算法,然后于1974年1月推出。DCT是最广泛使用的有损压缩方法,并且用于图像(例如JPEG和HEIF)、视频(例如MPEG、AVC和HEVC)和音频(例如MP3、AAC和Vorbis)。
有损图像压缩用于数码相机,以增加存储容量。同样,DVD、蓝光和流媒体视频使用有损视频编码格式。有损压缩广泛用于视频。
在有损音频压缩中,心理声学的方法用于去除音频信号的非可听(或较少可听)分量。人类语音的压缩通常使用更专业的技术进行;语音编码是区别于通用音频压缩的一门独立学科。语音编码用于互联网电话,例如,音频压缩用于CD翻录并由音频播放器解码。
有损压缩会导致代损失。
数据压缩的理论
编辑压缩的理论基础由信息论提供,更具体地说,是用于无损压缩的算法信息理论和用于有损压缩的率失真理论。这些研究领域基本上是由克劳德·香农(ClaudeShannon)创建的,他在1940年代末和1950年代初发表了有关该主题的基础论文。与压缩相关的其他主题包括编码理论和统计推断。
机器学习
机器学习和压缩之间有着密切的联系。在给定序列的整个历史的情况下预测序列后验概率的系统可用于优化数据压缩(通过对输出分布使用算术编码)。最佳压缩器可用于预测(通过找到压缩最佳的符号,给定先前的历史记录)。这种等价性已被用作使用数据压缩作为“通用智能”基准的理由。
另一种观点可以显示压缩算法将字符串隐式映射到隐式特征空间向量,并且基于压缩的相似性度量计算这些特征空间内的相似性。对于每个压缩器C(.),我们定义了一个相关的向量空间ℵ,使得C(.)映射一个输入字符串x,对应于向量范数||~x||。空间排除了对所有压缩算法背后的特征空间的详尽检查;相反,特征向量选择检查三种代表性的无损压缩方法,LZW、LZ77和PPM。
根据AIXI理论,在HutterPrize中更直接解释的一个连接,x的最佳可能压缩是生成x的最小可能的软件。例如,在该模型中,一个zip文件的压缩大小包括zip文件和解压软件,因为没有两者就无法解压它,但可能有更小的组合形式。
数据差异
数据压缩可以看作是数据差分的一种特殊情况。数据差异包括在给定源和目标的情况下产生差异,修补在给定源和差异的情况下再现目标。由于数据压缩中没有分离的源和目标,因此可以将数据压缩视为与空源数据的数据差异,压缩文件对应于从无到有的差异。这与将xxx熵(对应于数据压缩)视为相对熵的特例相同(对应于数据差分)没有初始数据。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/130314/