
死锁
编辑在并发计算中,死锁是指某些实体组中的任何成员都无法继续执行的任何情况,因为每个实体都在等待另一个成员(包括它自己)采取行动,例如发送消息,或者更常见的是释放锁。 死锁是多处理系统、并行计算和分布式系统中的常见问题,因为在这些上下文中,系统通常使用软件或硬件锁来仲裁共享资源并实现进程同步。
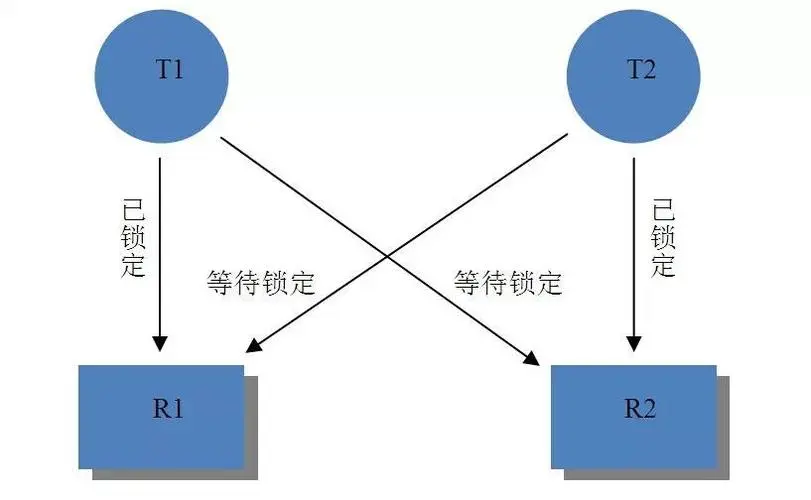
在操作系统中,死锁发生在进程或线程进入等待状态时,因为请求的系统资源被另一个等待进程持有,而该等待进程又在等待另一个等待进程持有的资源。 如果一个进程因为它请求的资源正在被另一个本身正在等待的进程使用而无限期地无法改变它的状态,那么系统就被称为死锁。
在通信系统中,死锁的发生主要是由于信号丢失或损坏,而不是资源争用。
死锁的个别必要条件和共同充分条件
编辑只有在系统中同时出现以下所有情况时,才会出现资源死锁情况:
- 互斥:至少一个资源必须以不可共享的模式持有; 也就是说,一次只有一个进程可以使用该资源。 否则,不会阻止进程在必要时使用资源。 在任何给定时刻,只有一个进程可以使用该资源。
- 持有并等待或资源持有:一个进程当前持有至少一种资源并请求其他进程持有的额外资源。
- 无抢占:资源只能由持有它的进程自愿释放。
- 循环等待:每个进程都必须等待另一个进程持有的资源,而另一个进程又在等待第一个进程释放资源。 一般来说,有一组等待进程,P = {P1, P2, …, PN},这样 P1 正在等待 P2 持有的资源,P2 正在等待 P3 持有的资源等等,直到 PN 等待 P1 持有的资源。
这四个条件被称为 Coffman 条件,源自 Edward G. Coffman, Jr. 在 1971 年的一篇文章中对它们的首次描述。
虽然这些条件足以在单实例资源系统上产生死锁,但它们仅表明在具有多个资源实例的系统上有可能发生死锁。
死锁处理
编辑大多数当前操作系统无法防止死锁。 当死锁发生时,不同的操作系统以不同的非标准方式对其作出响应。 大多数方法的工作原理是防止四种常见情况中的一种发生,尤其是第四种。 主要做法如下。
忽略死锁
编辑在这种方法中,假定永远不会发生死锁。 这也是鸵鸟算法的一个应用。 这种方法最初由 MINIX 和 UNIX 使用。 当死锁发生的时间间隔很大并且每次造成的数据丢失是可以容忍的时候使用。
如果死锁被正式证明永远不会发生,则可以安全地忽略死锁。 RTIC 框架就是一个例子。
检测
编辑在死锁检测下,允许死锁发生。 然后检查系统的状态以检测是否发生了死锁并随后对其进行了更正。 采用一种算法来跟踪资源分配和进程状态,它回滚并重新启动一个或多个进程以消除检测到的死锁。 由于操作系统的资源调度程序已知每个进程已锁定和/或当前请求的资源,因此很容易检测到已经发生的死锁。
检测到死锁后,可以使用以下方法之一进行更正:
- 进程终止:死锁中涉及的一个或多个进程可能会被中止。 可以选择中止死锁中涉及的所有竞争进程。 这确保了死锁的确定和快速解决。 但是代价很高,因为部分计算会丢失。 或者,可以选择一次中止一个进程,直到解决死锁。 这种方法的开销很高,因为在每次中止之后,算法都必须确定系统是否仍处于死锁状态。 在选择终止候选人时必须考虑几个因素,例如流程的优先级和年龄。
- 资源抢占:分配给各个进程的资源可能会被依次抢占并分配给其他进程,直到死锁被打破。
预防
编辑死锁预防通过防止四种科夫曼条件之一的发生来起作用。
- 去掉互斥条件意味着没有进程w
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/198037/