潜在类别模型
编辑在统计学中,潜在类模型 (LCM) 将一组观察到的(通常是离散的)多变量变量与一组潜在变量相关联。 它是一种潜在变量模型。 它被称为潜在类模型,因为潜在变量是离散的。 一个类别的特征是条件概率模式,该模式表明变量取特定值的可能性。
潜在类分析 (LCA) 是结构方程模型的一个子集,用于在多变量分类数据中查找案例的组或子类型。 这些子类型称为潜在类。
面对如下情况,研究人员可能会选择使用 LCA 来理解数据:假设已经在患有 X、Y 和 Z 疾病的一系列患者中测量了症状 a-d,并且疾病 X 与存在相关 症状 a、b 和 c,疾病 Y 具有症状 b、c、d,疾病 Z 具有症状 a、c 和 d。
LCA 将尝试检测潜在类别(疾病实体)的存在,从而在症状中创建关联模式。 与在因素分析中一样,LCA 也可用于根据xxx似然类别成员对案例进行分类。
因为解决 LCA 的标准是实现潜在类别,其中一个症状与另一个症状不再有任何关联(因为类别是导致它们关联的疾病),以及患者患有的疾病集(或类别 a case is a member of) 导致症状关联,症状将是有条件独立的,即,以类成员身份为条件,它们不再相关。
型号
编辑在每个潜在类别中,观察到的变量在统计上是独立的。 这是一个重要的方面。 通常观察到的变量在统计上是相关的。 通过引入潜在变量,在类内变量是独立的(局部独立性)的意义上恢复了独立性。 然后我们说观察到的变量之间的关联由潜在变量的类别来解释 (McCutcheon, 1987)。
其中 T {\displaystyle T} 是潜在类别的数量,而 p t {\displaystyle p_{t}} 是所谓的招募者无条件概率,应该总和为一。 p i n , t n {\displaystyle p_{i_{n},t}{n}} 是边际或条件概率。
这种双向模型与概率潜在语义分析和非负矩阵分解有关。
相关方法
编辑有许多具有不同名称和用途的方法具有共同的关系。 与 LCA 一样,聚类分析用于在数据中发现类群类案例组。 多元混合估计 (MME) 适用于连续数据,并假设此类数据来自混合分布:想象一组身高来自男性和女性的混合。 如果多元混合估计受到约束,使得每个分布中的度量必须不相关,则称为潜在剖面分析。 经过修改以处理离散数据,这种受约束的分析被称为 LCA。 离散的潜在特征模型进一步限制类别从单一维度的片段形成:本质上是将成员分配给该维度的类别:一个例子是根据能力或优点的维度将案例分配给社会类别。
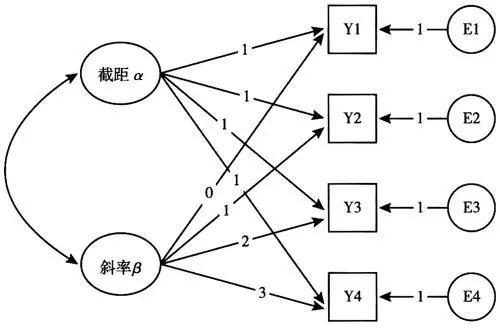

作为一个实际例子,变量可以是政治问卷的多项选择项目。 本例中的数据由一个 N 向列联表组成,其中包含许多受访者对项目的答案。 给定组成员资格,条件概率指定选择某些答案的机会。
申请
编辑LCA 可用于许多领域,例如:协同过滤、行为遗传学和诊断测试评估。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/204089/