
神经机器翻译
编辑神经机器翻译(NMT)是一种机器翻译方法,它使用人工神经网络来预测单词序列的可能性,通常在单个集成模型中对整个句子进行建模。
属性
编辑它们仅需要传统统计机器翻译(SMT)模型所需内存的一小部分。此外,与常规翻译系统不同,神经翻译模型的所有部分都经过(端到端)联合训练,以最大化翻译性能。
工作原理
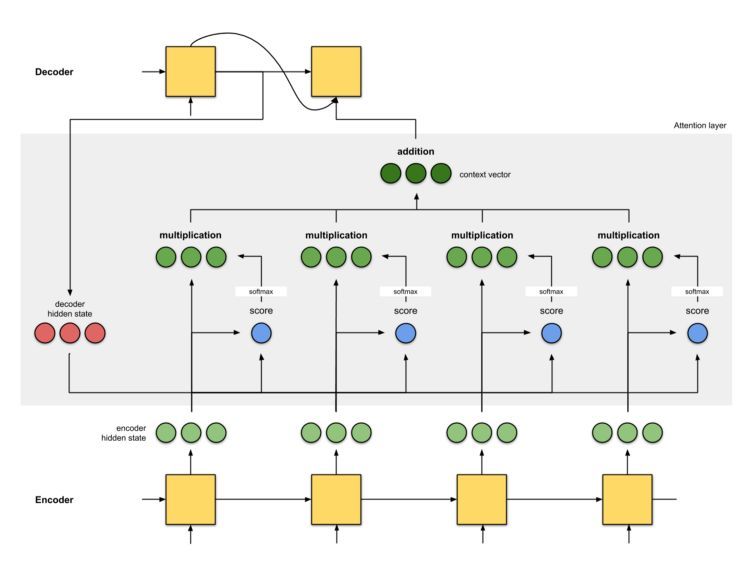
编辑神经机器翻译不同于使用单独设计的子组件的基于短语的统计方法。神经机器翻译(NMT)并非在统计机器翻译(SMT)的传统方法之外的艰巨步骤。它的主要偏离是对单词和内部状态使用矢量表示形式(“嵌入”、“连续空间表示形式”)。模型的结构比基于短语的模型更简单。没有单独的语言模型,翻译模型和重新排序模型,而只有一个序列模型可以一次预测一个单词。然而,该序列预测以整个源句子和整个已经产生的目标序列为条件。神经机器翻译模型使用深度学习和表征学习。
首先,通常使用递归神经网络(RNN)进行单词序列建模。该神经网络使用称为编码器的双向递归神经网络对第二RNN的源句进行编码,该第二RNN被称为解码器,用于预测目标语言中的单词。递归神经网络在将长输入编码为单个向量时面临困难。这可以通过注意力机制来补偿这使得解码器可以在生成输出的每个字的同时专注于输入的不同部分。还有其他覆盖模型可以解决此类关注机制中的问题。例如忽略过去的对齐信息,从而导致翻译过度和翻译不足。
对于长连续序列,卷积神经网络(Convnets)原则上更好一些,但是由于一些弱点,最初并未使用。这些通过使用“注意机制”在2017年得到了成功的补偿。
基于注意力的模型,转换器架构仍然是几种语言对的主要架构。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/111013/