基于能量的模型
编辑基于能量的模型(EBM)是一种直接从统计物理学中导入学习的生成模型(GM)形式。GM通过分析一个样本数据集来学习一个基础数据分布。一旦经过训练,GM就可以产生同样符合数据分布的其他数据集。EBM为这种学习的许多概率和非概率方法提供了一个统一的框架,特别是用于训练图形和其他结构化模型。EBM学习目标数据集的特征,并生成一个类似但更大的数据集。EBM检测数据集的潜在变量并生成具有类似分布的新数据集。目标应用包括自然语言处理、机器人学和计算机视觉。
基于能量的模型的历史
编辑早期的EBM工作提出了将能量表示为潜在变量和可观察变量的组成的模型。EBMs于2003年出现。方法EBMs通过将一个非标准化的概率标量(能量)与观察变量和潜在变量组合的每个配置联系起来,来捕获依赖关系。推断包括寻找潜伏变量的(值),这些潜伏变量在给定一组观察变量(值)的情况下能量最小。同样,该模型学习一个函数,将低能量与潜变量的正确值联系起来,而将高能量与不正确的值联系起来。传统的EBM依赖于随机梯度白化(SGD)优化方法,这些方法通常难以应用于高维数据集。2019年,OpenAI公开了一个变种,改为使用朗文动力学(LD)。LD是一种迭代优化算法,将噪声引入估计器,作为学习目标函数的一部分。它可以通过产生后验分布的样本来用于贝叶斯学习场景。EBMs不要求能量被归一化为概率。换句话说,能量不需要和为1。由于不需要像概率模型那样估计归一化常数,某些形式的推理和EBM的学习更具有可操作性和灵活性。样本是通过马尔科夫链蒙特卡洛方法隐式生成的。过去图像的回放缓冲器与LD一起用于初始化优化模块。
基于能量的模型的特征
编辑EBM展示了有用的特性。简单性和稳定性-EBM是xxx需要设计和训练的对象。独立的网络不需要被训练以确保平衡。自适应的计算时间-EBM可以产生尖锐的、多样化的样本或(更快)粗糙的、不那么多样化的样本。在时间无限的情况下,这个程序会产生真实的样本。灵活性--在变异自动编码器(VAE)和基于流量的模型中,生成器学习一个从连续空间到包含不同数据模式的(可能)不连续空间的映射。EBM可以学习将低能量分配给不相干的区域(多种模式)。
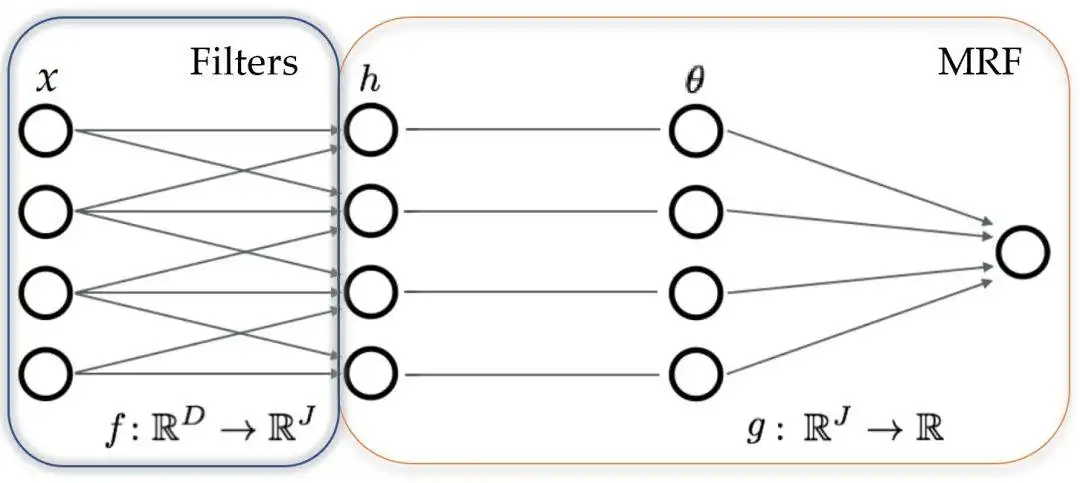

自适应生成-EBM生成器由概率分布隐含地定义,并随着分布的变化自动适应(无需训练),允许EBM解决生成器训练不实际的领域,以及最小化模式崩溃和避免来自分布外样本的虚假模式。构成性-单个模型是未归一化的概率分布,允许模型通过专家产品或其他分层技术进行组合。实验结果在图像数据集上,如CIFAR-10和ImageNet32x32,EBM模型相对快速地生成高质量的图像。它支持结合从一种类型的图像中学到的特征来生成其他类型的图像。它能够使用分布之外的数据集进行归纳,比基于流量的模型和自回归模型更有优势。EBM对对抗性扰动有相对的抵抗力,比明确针对它们进行分类训练的模型表现更好。替代品EBM与变异自动编码器(VAE)或生成对抗性神经网络(GAN)等技术竞争。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/175606/