简介
编辑线性判别分析 (LDA)、正态判别分析 (NDA) 或判别函数分析是 Fisher 线性判别法的推广,一种用于统计学和其他领域的方法,用于寻找特征的线性组合来表征或区分两个特征或更多类的对象或事件。
得到的组合可以用作线性分类器,或者更常见的是,用于在以后分类之前进行降维。
LDA 与方差分析 (ANOVA) 和回归分析密切相关,后者也试图将一个因变量表示为其他特征或测量值的线性组合。 但是,ANOVA 使用分类自变量和连续因变量,而判别分析具有连续自变量和分类因变量(即类标签)。 与方差分析相比,逻辑回归和概率回归更类似于 LDA,因为它们还通过连续自变量的值来解释分类变量。 这些其他方法在不合理假设自变量服从正态分布(LDA 方法的基本假设)的应用中更可取。
LDA 还与主成分分析 (PCA) 和因子分析密切相关,因为它们都寻找最能解释数据的变量的线性组合。 LDA 明确尝试对数据类别之间的差异进行建模。 相反,PCA 不考虑类中的任何差异,因素分析基于差异而非相似性构建特征组合。 判别分析也不同于因子分析,因为它不是一种相互依赖的技术:必须区分自变量和因变量(也称为标准变量)。
当对每个观察的自变量进行的测量是连续量时,LDA 起作用。 在处理分类自变量时,等效技术是判别对应分析。
当组是先验已知的(与聚类分析不同)时,使用判别分析。 每个个案必须有一个或多个定量预测指标的分数,以及一个组指标的分数。 简单来说,判别函数分析就是分类——将事物分配到相同类型的组、类或类别中的行为。
历史
编辑最初的二分判别分析是由 Ronald Fisher 爵士于 1936 年开发的。它不同于 ANOVA 或 MANOVA,它用于通过一个或多个独立的分类变量来预测一个(ANOVA)或多个(MANOVA)连续因变量。 判别函数分析可用于确定一组变量是否有效预测类别成员资格。
两个类的LDA
编辑考虑一组观测值 x → {\displaystyle {\vec {x}}}(也称为特征、属性、变量或测量),用于已知类 y {\displaystyle y} 的对象或事件的每个样本。 这组样本称为训练集。 然后,分类问题是在仅给定观察值 x → {\displaystyle {\vec { X}}} 。
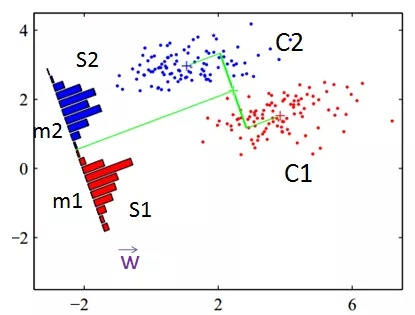

在没有任何进一步假设的情况下,生成的分类器称为二次判别分析 (QDA)。
LDA 改为进行额外的简化同方差假设(即类协方差相同,因此 Σ 0 = Σ 1 = Σ {\displaystyle \Sigma _{0}=\Sigma _{1}=\Sigma } ) 并且协方差具有满秩。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/204091/