
相对熵
编辑在数理统计中,相对熵(也称为相对熵和 I-散度),表示为 D KL ( P ∥ Q ) {dISPlaystyle D_{TeXt{KL}}(Pparallel Q)} ,是一个 统计距离的类型:衡量一个概率分布 P 与第二个参考概率分布 Q 的不同之处。P 与 Q 的 KL 散度的简单解释是当实际分布时使用 Q 作为模型的预期过度惊喜 是 P。虽然它是一个距离,但它不是度量,最熟悉的距离类型:它在两个分布中不对称(与信息的变化相反),并且不满足三角不等式。 相反,就信息几何而言,它是一种散度,是平方距离的推广,并且对于某些类别的分布(特别是指数族),它满足广义勾股定理(适用于平方距离)。
在简单情况下,相对熵为 0 表示所讨论的两个分布具有相同数量的信息。 相对熵是两个分布或度量的非负函数。 它在理论上有多种应用,例如表征信息系统中的相对(香农)熵、连续时间序列中的随机性以及比较推理统计模型时的信息增益; 和实践,如应用统计学、流体力学、神经科学和生物信息学。
简介和背景
编辑考虑两个概率分布 P {diSPlaystyle P} 和 Q {displaystyle Q} 。 通常,P {displaystyle P} 表示数据、观察值或测量的概率分布。 分布 Q {displaystyle Q} 代表 P {displaystyle P} 的理论、模型、描述或近似。 然后,相对稀被解释为使用为 Q {displaystyle Q} 优化的代码而不是为 P {displaystyle P 优化的代码对 P {displaystyle P} 的样本进行编码所需的位数的平均差异 } 。 请注意,P {displaystyle P} 和 Q {displaystyle Q} 的角色在某些更容易计算的情况下可以颠倒,例如使用期望最大化(EM)算法和证据下限(ELBO) )计算。
词源
编辑在 Kullback (1959) 中,对称形式再次称为散度,每个方向的相对熵称为 作为两个分布之间的定向分歧; Kullback 更喜欢术语歧视信息。 术语散度与距离(度量)相反,因为对称散度不满足三角不等式。 Kullback (1959, pp. 6–7, 1.3 Divergence) 中提供了大量关于早期使用对称散度和其他统计距离的参考资料。 不对称的定向散度已被称为相干散度,而对称的定向散度现在被称为杰弗里斯散度。
定义
编辑对于在同一概率空间 X {displaystyle {mathcal {X}}} 上定义的离散概率分布 P {displaystyle P} 和 Q {displaystyle Q} ,来自 Q {displaystyle Q} 到 P {displaystyle P} 定义
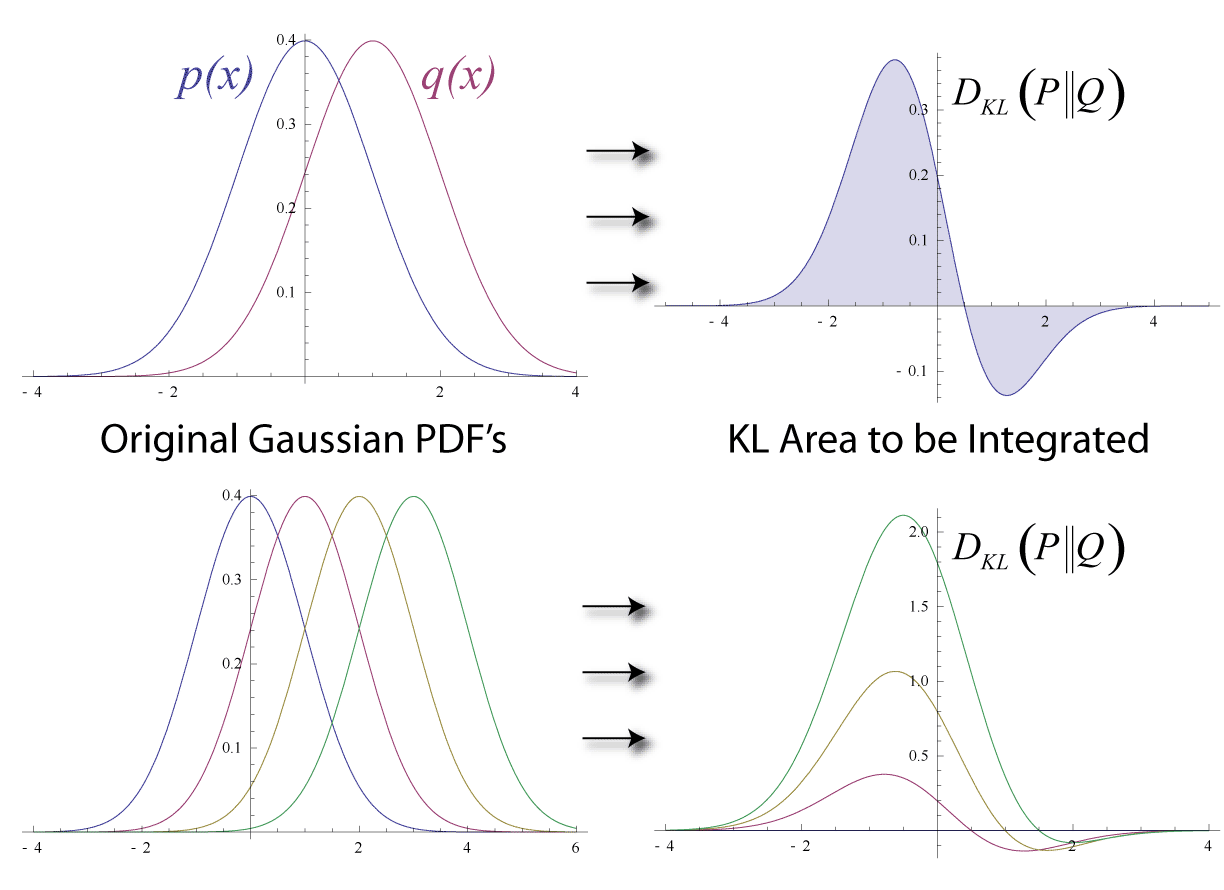
换句话说,它是概率 P {displaystyle P} 和 Q {displaystyle Q} 之间的对数差的期望,其中期望是使用概率 P {displaystyle P} 获得的。
相对熵的定义仅当对于所有 x {displaystyle x} , Q ( x ) = 0 {displaystyle Q(x)=0} 意味着 P ( x ) = 0 {displaystyle P(x)= 0}(绝对连续性)。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/216418/