
简介
编辑Bidirectional Encoder Representations from Transformers (BERT) 是一种基于变压器的机器学习技术,用于自然语言处理 (NLP) 预训练,由 GOOGLE 开发。
BERT 由 Jacob Devlin 和他的 Google 同事于 2018 年创建并发布。
2019 年,谷歌宣布已开始在其搜索引擎中使用 BERT,到 2020 年底,它几乎在所有英语查询中都使用了 BERT。
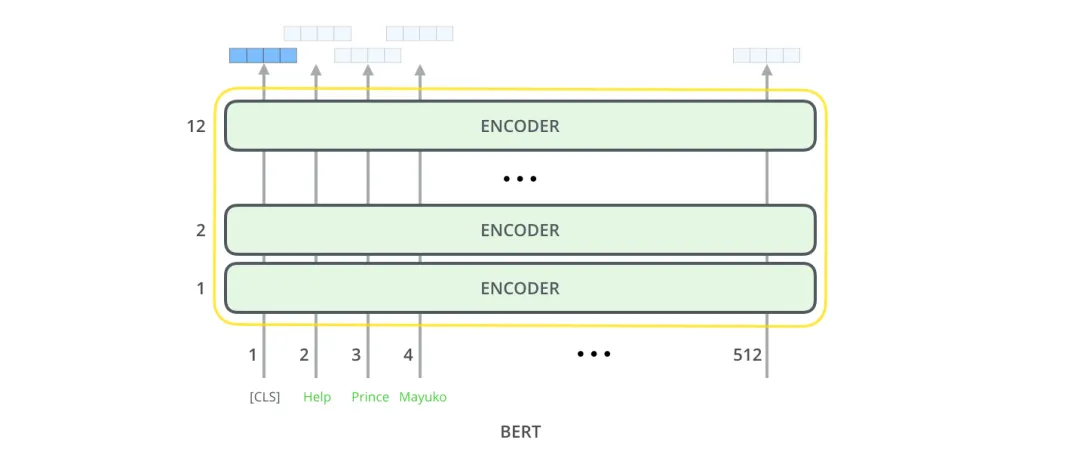
原始的英文 BERT 有两种模型:(1) BERTBASE:12 个编码器和 12 个双向自注意头,以及 (2) BERTLARGE:24 个编码器和 16 个双向自注意头。
架构
编辑BERT 的核心是一个变换器语言模型,具有可变数量的编码器层和自注意力头。该架构几乎与 Vaswani 等人的原始转换器实现相同。
BERT 接受了两项任务的预训练:语言建模和下一句预测。作为训练过程的结果,BERT 学习了单词的上下文嵌入。经过计算量大的预训练后,可以使用较少的资源在较小的数据集上对 BERT 进行微调,以优化其在特定任务上的性能。
性能
编辑当 BERT 发布时,它在许多自然语言理解任务上取得了最先进的性能:
- GLUE(通用语言理解评估)任务集(由 9 个任务组成)
- SQuAD(斯坦福问答数据集)v1.1 和 v2.0
- SWAG(对抗性世代的情况)
- 情感分析:基于 BERT 的情感分类器在多种语言中取得了显着的性能
分析
编辑BERT 在这些自然语言理解任务上表现出色的原因尚不清楚。 目前的研究主要集中在调查 BERT 输出背后的关系,作为精心选择的输入序列的结果,通过探测分类器分析内部向量表示,以及注意力权重表示的关系。
历史
编辑BERT 起源于预训练上下文表示,包括半监督序列学习、生成预训练、ELMo 和 ULMFit。 与以前的模型不同,BERT 是一种深度双向、无监督的语言表示,仅使用纯文本语料库进行预训练。 word2vec 或 GloVe 等无上下文模型为词汇表中的每个单词生成单个单词嵌入表示,其中 BERT 会考虑给定单词每次出现的上下文。 例如,尽管在 He is running a company 和 He is running a marathon 这两个句子中,running 的向量都具有相同的 word2vec 向量表示,而 BERT 将根据句子提供不同的上下文嵌入。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/189803/