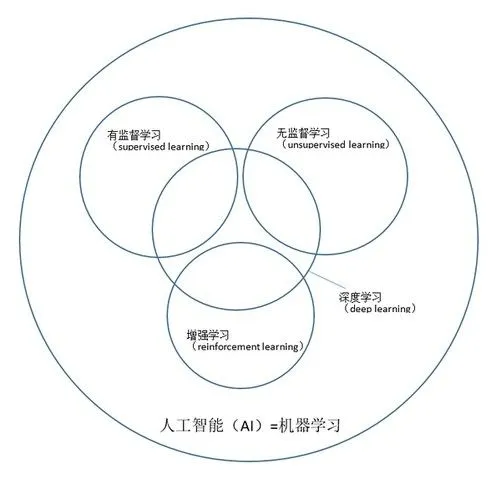
机器学习
编辑机器学习(ML)是一个致力于理解和建立"学习"方法的研究领域,也就是说,利用数据来提高某些任务的性能的方法。它被看作是人工智能的一部分。机器学习算法基于样本数据(称为训练数据)建立一个模型,以便在没有明确编程的情况下做出预测或决定。机器学习算法被广泛应用于医学、电子邮件过滤、语音识别、农业和计算机视觉等领域,在这些领域中,开发传统算法来完成所需的任务是困难的或不可行的。机器学习的一个子集与计算统计学密切相关,它侧重于使用计算机进行预测,但并非所有机器学习都是统计学习。数学优化的研究为机器学习领域提供了方法、理论和应用领域。数据挖掘是一个相关的研究领域,专注于通过无监督学习进行探索性数据分析。机器学习的一些实现方式以模仿生物大脑工作的方式使用数据和神经网络。在商业问题的应用中,机器学习也被称为预测性分析。
机器学习的概述
编辑学习算法的工作基础是,过去行之有效的策略、算法和推论有可能在未来继续行之有效。这些推论可以是显而易见的,例如,在过去的一万天里,太阳每天早上都会升起,所以它可能在明天早上也会上升。它们可以是细微的,例如X%的家族有地理上独立的物种,有颜色变异,所以有Y%的机会存在未发现的黑天鹅。机器学习程序可以在没有明确编程的情况下执行任务。它涉及计算机从提供的数据中学习,从而执行某些任务。对于分配给计算机的简单任务,可以通过编程算法告诉机器如何执行解决手头问题所需的所有步骤;就计算机而言,不需要学习。对于更高级的任务,由人类手动创建所需的算法可能是一个挑战。在实践中,帮助机器开发自己的算法,而不是让人类程序员指定每一个需要的步骤,可能会变得更加有效。机器学习这门学科采用了各种方法来教计算机完成没有完全令人满意的算法的任务。在存在大量潜在答案的情况下,一种方法是将一些正确答案标记为有效答案。然后,这可以作为计算机的训练数据,以改进它用来确定正确答案的算法。例如,为了训练数字字符识别任务的系统,经常使用MNIST的手写数字数据集。历史和与其他领域的关系机器学习一词是由IBM员工、计算机游戏和人工智能领域的先驱阿瑟-塞缪尔于1959年创造的。同时,自学计算机的同义词也在这个时期被使用。到20世纪60年代初,雷神公司开发了一种带有打孔磁带存储器的实验性学习机,称为赛博坦,可以使用初级强化学习来分析声纳信号、心电图和语音模式。它由人类操作员/教师反复训练,以识别模式,并配备了一个傻瓜按钮,使其重新评估错误的决定。20世纪60年代,关于机器学习研究的代表性书籍是尼尔森的《学习机器》一书,主要涉及模式分类的机器学习。

与模式识别有关的兴趣一直持续到70年代,正如Duda和Hart在1973年所描述的那样。1981年,一份关于使用教学策略使神经网络学会从计算机终端识别40个字符(26个字母、10个数字和4个特殊符号)的报告。TomM.Mitchell为机器学习领域研究的算法提供了一个被广泛引用的、更正式的定义。如果一个计算机程序在T类任务中的表现,正如P所衡量的那样,随着经验E的增加而提高,那么它就被称为从经验E中学习。这遵循了阿兰-图灵在他的论文《计算机械与智能》中的建议,即用"机器能做我们(作为思考实体)能做的事吗?"来取代机器能思考的问题。现代的机器学习有两个目标,一个是根据已经开发的模型对数据进行分类,另一个目的是进行预测。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/175420/