
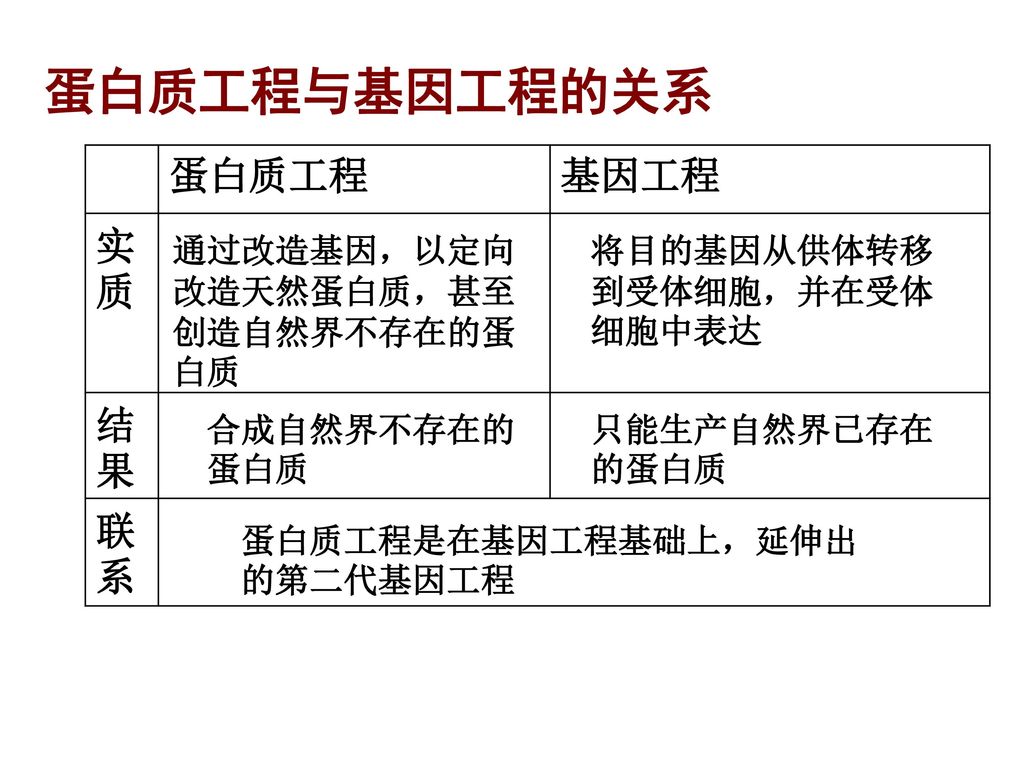
什么是蛋白质工程
编辑蛋白质工程是开发有用或有价值的蛋白质的过程。它是一门年轻的学科,正在对蛋白质折叠的理解和蛋白质设计原理的识别方面进行大量研究。它也是一个产品和服务市场,到2017年估计价值为1,680亿美元。
蛋白质工程有两种通用策略:合理的蛋白质设计和定向进化。这些方法不是互斥的。研究人员经常会同时使用这两种方法。将来,对蛋白质结构和功能的更详细了解以及高通量筛选的进步可能会大大扩展蛋白质工程的能力。最终,甚至可以通过较新的方法(包括扩展的遗传密码)包括非天然氨基酸,该方法允许以遗传密码编码新氨基酸。
(adsbyGOOGLE = window.adsbygoogle || []).push({});
方法
编辑合理设计
编辑在合理的蛋白质设计中,科学家利用蛋白质的结构和功能的详细知识来进行所需的改变。通常,这具有便宜且技术上容易的优点,因为定点诱变方法得到了很好的发展。然而,其主要缺点是通常无法获得蛋白质的详细结构知识,并且即使可获得,也很难预测各种突变的影响,因为结构信息通常会提供蛋白质结构的静态图片。但是,诸如Folding @ home和Foldit之类的程序已利用众包技术来深入了解蛋白质的折叠基序。
计算蛋白质设计算法力图确定折叠到预定目标结构时能量低的新型氨基酸序列。尽管需要搜索的序列构象空间很大,但计算蛋白质设计的最大挑战性要求是快速但准确的能量函数,该函数可以将最佳序列与相似的次优序列区分开。
多序列比对
编辑如果没有有关蛋白质的结构信息,则序列分析通常可用于阐明有关蛋白质的信息。这些技术涉及靶蛋白序列与其他相关蛋白序列的比对。这种比对可以显示出哪些氨基酸在物种之间是保守的,并且对于蛋白质的功能很重要。这些分析可以帮助识别可以用作突变目标位点的热点氨基酸。多序列比对利用诸如PREFAB、SABMARK、OXBENCH、IRMBASE和BALIBASE的数据库,以使参照靶蛋白序列与已知序列交叉。下面列出了多种序列比对技术。
该方法开始于使用k元组或Needleman-Wunsch方法执行序列的成对比对。这些方法计算的矩阵描述了序列对之间的成对相似性。然后将相似度分数转换为距离分数,使用邻居加入方法将其用于生成引导树。然后采用该指导树来产生多序列比对。
半理性设计
编辑半合理设计结合预测算法使用有关蛋白质序列,结构和功能的信息。这些一起用于鉴定最有可能影响蛋白质功能的靶氨基酸残基。这些关键氨基酸残基的突变产生了更可能具有增强特性的突变蛋白文库。
半理性酶工程学和从头酶设计的进步为研究人员提供了有效而有效的新策略来操纵生物催化剂。已经证明在库设计中整合基于序列和结构的方法是酶重新设计的重要指南。通常,当前的从头计算和重新设计方法在催化性能上无法与进化的变体进行比较。尽管可以使用定向进化来进行实验优化,但是通过改进设计算法,可以实现结构预测准确性的进一步提高和更大的催化能力。通过集成蛋白质动力学,进一步的功能增强可能会包含在将来的模拟中。
生化和生物物理研究以及预测框架的微调将有助于实验评估单个设计功能的功能意义。更好地理解这些功能贡献将为改进未来的设计提供反馈。
尽管蛋白质的计算设计已经从根本上改变了蛋白质工程可以操纵生物大分子的方式,但是定向进化可能不会被替代为蛋白质工程的选择方法。通过使用结合了假设驱动的蛋白质工程的预测框架的方法,可以生成更小,更集中且功能更丰富的库。新的设计策略和技术进步已开始背离传统协议,例如定向进化,它是识别集中库中表现最佳的候选人的最有效策略。全基因文库合成正在取代改组文库的改组和诱变方案。高特异性的低通量筛选测定法也越来越多地用于代替数百万名候选人的巨大筛选和选择工作。总之,这些进展有望使蛋白质工程超越定向进化,朝着定制生物催化剂的实用,更有效的策略发展。
筛选和选择技术
编辑一旦蛋白质经历了定向进化,定量设计或半定量设计,就必须筛选突变体蛋白的文库,以确定哪些突变体显示出增强的特性。噬菌体展示方法是筛选蛋白质的一种选择。该方法涉及将编码变体多肽的基因与噬菌体外壳蛋白基因融合。通过在体外与固定的靶标结合来选择在噬菌体表面表达的蛋白质变体。然后在细菌中扩增具有选定蛋白质变体的噬菌体,然后通过酶联免疫吸附测定法鉴定阳性克隆。然后将这些选择的噬菌体进行DNA测序。
细胞表面展示系统也可用于筛选突变多肽文库。将文库突变基因掺入表达载体中,然后将其转化成合适的宿主细胞。对这些宿主细胞进行进一步的高通量筛选方法,以鉴定具有所需表型的细胞。
已经开发了无细胞展示系统以利用体外蛋白质翻译或无细胞翻译。这些方法包括MRNA展示,核糖体展示,共价和非共价DNA展示以及体外区室化。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/109180/