过度拟合
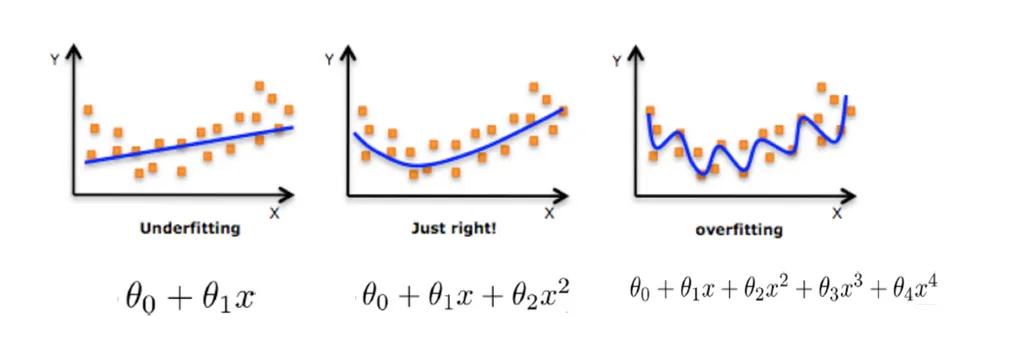
编辑在数学建模中,过度拟合是指产生的分析结果与一组特定的数据过于接近或完全对应,因此可能无法拟合其他数据或可靠地预测未来的观察结果。过度拟合模型是指一个数学模型所包含的参数多于数据所能证明的。过度拟合的本质是在不知不觉中提取了一些残余变异(即噪声),好像这些变异代表了潜在的模型结构。当一个数学模型不能充分捕捉到数据的基本结构时,就会发生欠拟合。拟合不足的模型是指在一个正确指定的模型中会出现的一些参数或条款缺失的模型。例如,当对非线性数据进行线性模型拟合时,就会出现欠拟合的情况。这样的模型往往会有很差的预测性能。过度拟合的可能性之所以存在,是因为用于选择模型的标准与用于判断模型是否合适的标准不一样。例如,一个模型可能是通过在某组训练数据上的性能最大化来选择的,然而它的适合性可能是由它在未见过的数据上的性能决定的;那么,当一个模型开始记忆训练数据而不是学习从趋势中归纳时,就会出现过度拟合。作为一个极端的例子,如果参数的数量与观察值的数量相同或更多,那么一个模型仅仅通过记忆全部的数据就可以完美地预测训练数据。(见图2。)不过,这样的模型在进行预测时通常会严重失败。过度拟合的可能性不仅取决于参数和数据的数量,而且还取决于模型结构与数据形状的一致性,以及与数据中预期的噪声或误差水平相比,模型误差的大小。即使拟合的模型没有过多的参数,可以预见的是,拟合关系在新的数据集上的表现将不如在用于拟合的数据集上的表现(这种现象有时被称为缩减)。特别是,相对于原始数据而言,决定系数的值会缩减。为了减少过拟合的机会或数量,有几种技术可用(例如,模型比较、交叉验证、正则化、早期停止、修剪、贝叶斯先验或剔除)。一些技术的基础是:(1)明确惩罚过于复杂的模型,或者(2)通过评估模型在一组未用于训练的数据上的表现来测试模型的泛化能力,这些数据被认为是模型将遇到的典型的未见过的数据。
统计推断
编辑在统计学中,推断来自一个统计模型,该模型是通过一些程序选择的。Burnham和Anderson在他们被广泛引用的关于模型选择的文章中认为,为了避免过度拟合,我们应该坚持Parsimony原则。作者还说到过度拟合的模型......在参数估计中往往没有偏差,但其估计的(和实际的)抽样方差却不必要地大(相对于用一个更简明的模型所能达到的精度,估计的精度很差)。虚假的治疗效果往往会被识别出来,而虚假的变量则被包含在过度拟合的模型中。通过适当平衡欠拟合和过度拟合的误差,可以得到一个最佳近似模型。当没有什么理论可以指导分析时,过拟合更有可能成为一个严重的问题,部分原因是那时往往有大量的模型可以选择。模型选择和模型平均化》一书(2008)是这样说的。给定一个数据集,按一下按钮就可以拟合数千个模型,但如何选择xxx的?

有了这么多候选模型,过度拟合是一个真正的危险。打出哈姆雷特的猴子实际上是个好作家吗?回归在回归分析中,过度拟合经常发生。作为一个极端的例子,如果线性回归中有p个变量,有p个数据点,那么拟合线可以完全穿过每个点。对于逻辑回归或Cox比例危险模型,有各种经验法则(如5-9、10和10-15--每个自变量有10个观测值的准则被称为十进一法则)。在回归模型的选择过程中,随机回归函数的平均平方误差可以分成随机噪声、近似偏差和回归函数的估计方差。偏差-方差的权衡常常被用来克服过拟合模型。在一大批实际上与被预测的因变量没有关系的解释变量中,一般来说,有些变量会被错误地发现具有统计学意义,而
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/175867/