
键盘扫描码
编辑扫描码(或扫描码)是大多数计算机键盘发送到计算机以报告按下了哪些键的数据。 键盘上的每个键都分配有一个数字或数字序列。
变体
编辑按行和列映射关键位置需要不太复杂的计算机硬件; 因此,在过去,使用软件或固件将扫描码转换为文本字符比通过文本字符连接键盘更便宜。 这种成本差异并不像以前那么大。 然而,许多类型的计算机仍然使用它们的传统扫描码来保持向后兼容性。
一些键盘标准包括每个被按下的键的扫描码和每个被释放的键的不同扫描码。 此外,许多键盘标准(例如,IBM PC 兼容标准)允许键盘本身通过让键盘本身在按住键时重复生成按键扫描码来生成打字重复键,并在按下时发送一次释放扫描码 钥匙被释放。
按键盘扫描码集
编辑在某些操作系统上,您可能会在计算机启动时通过按住某个键来发现某个键的按下扫描码。 运气好的话,扫描码(或其中的一部分)将在生成的卡住键错误消息中指定。 [注意:在 Windows 7 上只出现一个字节的扫描码。]
PC 兼容
编辑IBM PC 兼容计算机键盘上的是由键盘发送的 1 到 3 个字节的集合。 大多数字符键都有一个单字节扫描码; 执行特殊功能的键具有 2 字节或 3 字节扫描码,通常以字节(十六进制)E0、E1 或 E2 开头。 此外,几个键发送更长的扫描码,有效地模拟了一系列键,使不同类型的软件更容易处理。
PC 键盘因为 PS/2 键盘最多支持三个扫描码集。 最常遇到的是 XT(第 1 组)扫描码,它基于 IBM PC XT 及更早版本使用的 83 键键盘。 这些主要由一个字节组成; 低 7 位标识键,最高有效位为按键清除或设置为按键释放。 一些额外的键有一个 E0(或很少,E1 或 E2)前缀。 这些最初是分配的,因此忽略 E0 前缀(它在按键范围内,因此不会对不理解它们的操作系统产生影响)会产生合理的结果。 例如,数字小键盘的 Enter 键产生扫描码 E0 1C,对应于 Return 键的扫描码 1C。
IBM 3270 PC 引入了自己的一组扫描码(第 3 组),具有不同的键编号,并且键释放由 F0 前缀表示。 为了向后兼容,3270 PC 使用附加卡和 BIOS 扩展将这些转换为 XT(第 1 组)扫描码。 当 Linux 检测到可以正确支持扫描码集 3 的 PS/2 键盘时,默认情况下使用该集。
IBM PC AT 引入了 AT(第 2 组)扫描码。 在 84 键 AT 键盘上,这些键主要是第 3 组的一个子集,由于布局的修改造成了一些差异(例如,功能键的位置和扫描码发生了变化)。 由于 PC AT 添加的密钥通常在第 2 组和第 3 组中具有不同的扫描码,并且在第 2 组中经常具有 E0 或 E1 前缀。 同样,按键释放由 F0 前缀表示。
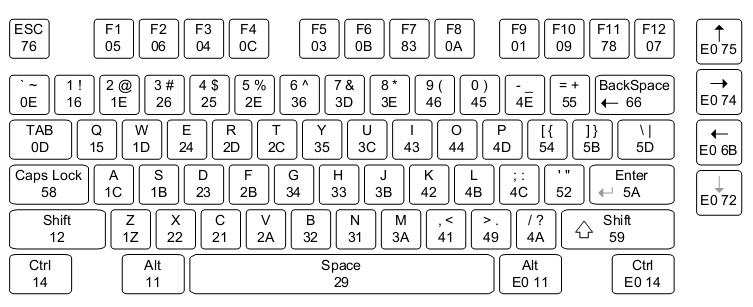
对于自 IBM PC AT 以来的计算机,主板上的键盘控制器以所谓的转换模式将 AT(第 2 组)扫描码转换为 XT(第 1 组)扫描码。 可以在直通模式下禁用此转换,从而可以看到原始扫描码。 因此,软件开发人员是否会在现代 PC 兼容机上遇到 AT 扫描码或 XT 扫描码取决于键盘的访问方式。
兼容的 PS/2 键盘可以被告知发送第 1、2 或 3 组中的扫描码。
USB
编辑USB 键盘使用一组新的扫描码,主要在 USB 标准中指定。 所有识别 USB 键盘的计算机都可以识别这些新的扫描码。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/197313/