
重复数据删除
编辑在计算中,重复数据删除是一种消除重复数据重复副本的技术。一个相关且有点同义的术语是单实例(数据)存储。此技术用于提高存储利用率,还可以应用于网络数据传输以减少必须发送的字节数。在重复数据删除过程中,将在分析过程中识别并存储唯一的数据块或字节模式。随着分析的继续,会将其他块与存储的副本进行比较,并且每当发生匹配时,冗余块就会被指向存储块的小引用替换。假设相同的字节模式可能出现数十次,数百次甚至数千次,则可以大大减少必须存储或传输的数据量。
重复数据删除与数据压缩算法(例如LZ77和LZ78)不同。压缩算法可以识别单个文件中的冗余数据并对其进行更有效的编码,而重复数据删除的目的是检查大量数据并识别相同的较大部分(例如整个文件或文件的较大部分),然后替换它们与共享副本。例如,典型的电子邮件系统可能包含100个具有相同1 MB(兆字节)文件附件的实例。每次发送电子邮件备份平台后,将保存附件的所有100个实例,需要100 MB的存储空间。使用重复数据删除时,实际上仅存储附件的一个实例。随后的实例将以大约100到1的重复数据删除率引用回保存的副本。重复数据删除通常与数据压缩配合使用以节省更多存储空间:重复数据删除首先用于消除大块重复数据,然后使用压缩来有效地消除重复数据。对每个存储的块进行编码。
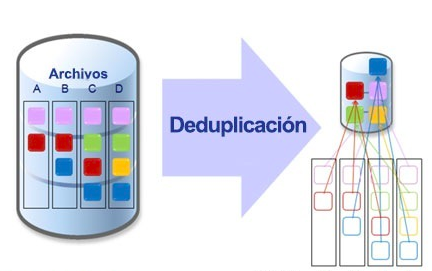
好处
编辑基于存储的重复数据删除减少了给定文件集所需的存储量。在非常相似或什至完全相同的数据的多个副本存储在单个磁盘上的应用程序中,这是一种最常见的方案,它最有效。对于数据备份,给定备份中的大多数数据与以前的备份保持不变。普通备份系统试图通过忽略(或硬链接)未更改的文件或存储差异来利用此漏洞文件之间。但是,这两种方法都无法捕获所有冗余。硬链接对仅以较小方式更改的大文件无济于事,例如电子邮件数据库。差异仅在单个文件的相邻版本中找到冗余。串联网络重复数据删除用于减少端点之间必须传输的字节数,这可以减少所需的带宽量。查看WAN优化了解更多信息。虚拟服务器和虚拟桌面可从重复数据删除中受益,因为它允许名义上将每个虚拟机的单独系统文件合并到单个存储空间中。同时,如果给定的虚拟机自定义文件,则重复数据删除将不会更改其他虚拟机上的文件-诸如硬链接或共享磁盘之类的替代产品不提供这种功能。类似地改善了备份或制作虚拟环境的副本。
分类
编辑后处理与在线重复数据删除
编辑重复数据删除可能会在数据流中“在线”发生,也可能在写入后进行“后处理”。
使用后处理重复数据删除,新数据首先存储在存储设备上,然后在以后的某个过程中将分析数据以查找重复数据。好处是无需在存储数据之前等待哈希计算和查找完成,从而确保存储性能不会降低。提供基于策略的操作的实现可以使用户能够推迟对“活动”文件进行优化,或者根据类型和位置来处理文件。一个潜在的缺点是重复数据可能会在短时间内不必要地存储,如果系统接近满容量,则可能会出现问题。
另外,重复数据删除哈希计算可以在线完成:当数据进入目标设备时同步。如果存储系统识别出已存储的块,则仅存储对现有块的引用,而不存储整个新块。
与重复数据删除相比,在线重复数据删除的优点在于,它需要较少的存储和网络流量,因为从不存储或传输重复数据。不利的一面是,哈希计算的计算量可能很大,从而降低了存储吞吐量。但是,某些具有串联重复数据删除功能的供应商已经展示了能够以高速率执行串联重复数据删除的设备。
后处理和在线重复数据删除方法经常引起激烈争论。
数据格式
编辑SNIA词典确定了两种方法:
- 与内容无关的重复数据删除-一种重复数据删除方法,不需要了解特定的应用程序数据格式。
- 内容感知的重复数据删除-一种利用特定应用程序数据格式的知识的重复数据删除方法。
源与目标重复数据删除
编辑分类重复数据删除方法的另一种方法是根据它们出现的位置。在创建数据的地方附近发生的重复数据删除称为“源重复数据删除”。当它在数据存储位置附近发生时,称为“目标重复数据删除”。
源重复数据删除可确保对数据源上的数据进行重复数据删除。这通常直接在文件系统内进行。文件系统将定期扫描创建散列的新文件,并将它们与现有文件的散列进行比较。当找到具有相同散列的文件时,将删除文件副本,新文件将指向旧文件。但是,与硬链接不同,重复的文件被认为是单独的实体,如果以后修改了重复的文件之一,则使用称为写时复制的系统将创建该更改的文件或块的副本。重复数据删除过程对用户和备份应用程序是透明的。备份重复数据删除的文件系统通常会导致重复,导致备份大于源数据。
可以为复制操作明确声明源重复数据删除,因为无需进行任何计算即可知道所复制的数据需要重复数据删除。这导致在文件系统上形成一种新的“链接”形式,称为reflink(Linux)或clonefile(MacOS),其中使一个或多个inode(文件信息条目)共享它们的部分或全部数据。它的命名类似于在inode级别工作的硬链接和在文件名级别工作的符号链接。[8]各个条目具有不混叠的写时复制行为,即事后更改一个副本不会影响其他副本。[9]微软的ReFS也支持此操作。
目标重复数据删除是在该位置未生成数据时删除重复数据的过程。这样的示例是连接到SAN / NAS的服务器,SAN / NAS将是服务器的目标(目标重复数据删除)。服务器不知道任何重复数据删除,服务器也是数据生成的重点第二个例子是备份。通常,这将是备份存储,例如数据存储库或虚拟磁带库。
重复数据删除方法
编辑重复数据删除实现的一种最常见形式是通过比较数据块以检测重复项来工作。为此,通常为每个数据块分配一个标识,该标识由软件计算得出,通常使用加密哈希函数。在许多实现中,假设如果标识相同,则数据相同,即使由于信鸽原理在所有情况下都不是正确的;其他实现不假定具有相同标识符的两个数据块是相同的,而是实际上验证具有相同标识的数据是相同的。如果软件假设重复数据删除名称空间中已经存在给定标识,或者根据实现方式实际验证两个数据块的身份,则它将用链接替换该重复数据块。
一旦对数据进行了重复数据删除,则在回读文件时,无论在哪里找到链接,系统都会简单地用引用的数据块替换该链接。重复数据删除过程旨在对最终用户和应用程序透明。
- 块。在某些系统中,块是由物理层约束(例如WAFL中的 4KB块大小)定义的。在某些系统中,仅比较完整的文件,这称为单实例存储或SIS。通常认为最智能(但占用大量CPU)的分块方法是滑动块。在滑块中,窗口沿文件流传递,以查找更自然发生的内部文件边界。
- 客户端备份重复数据删除。此过程是在源(客户端)计算机上最初创建重复数据删除哈希计算的过程。与目标设备中已经存在的文件具有相同哈希值的文件不会被发送,目标设备只是创建适当的内部链接来引用重复的数据。这样做的好处是它避免了不必要的数据通过网络发送,从而减少了通信量。
- 主存储和辅助存储。根据定义,主存储系统旨在获得最佳性能,而不是最低的成本。这些系统的设计标准是提高性能,但要以其他考虑为代价。此外,主存储系统对任何会对性能产生负面影响的操作的容忍度要低得多。同样根据定义,辅助存储系统主要包含数据的重复副本或辅助副本。这些数据副本通常不用于实际的生产操作,因此可以容忍某些性能下降,以换取提高的效率。
迄今为止,重复数据删除已主要用于辅助存储系统。其原因有两个。首先,重复数据删除需要开销来发现和删除重复数据。在主存储系统中,此开销可能会影响性能。重复数据删除应用于辅助数据的第二个原因是,辅助数据往往具有更多的重复数据。特别是备份应用程序通常会随着时间的流逝产生大量重复数据。
在系统设计不需要大量开销或不影响性能的某些情况下,重复数据删除已成功部署到主存储中。
单实例存储
编辑单实例存储(SIS)是系统获取内容对象的多个副本并将其替换为单个共享副本的功能。这是消除数据重复并提高效率的一种手段。SIS通常在文件系统,电子邮件服务器软件,数据 备份和其他与存储相关的计算机软件中实现。单实例存储是重复数据删除的简单变体。尽管重复数据删除可以在段或子块级别起作用,但是单实例存储在对象级别起作用,从而消除了对象的冗余副本,例如整个文件或电子邮件。
缺点和疑虑
编辑一种用于重复数据删除的方法依赖于使用加密哈希函数来识别重复的数据段。如果两个不同的信息生成相同的哈希值,则称为碰撞。冲突的可能性主要取决于哈希长度。因此,引起关注的是,如果发生散列冲突,则可能发生数据损坏,并且没有使用附加的验证手段来验证数据是否存在差异。在线和后处理体系结构都可以对原始数据进行逐位验证,以确保数据完整性。所使用的哈希函数包括一些标准,例如SHA-1,SHA-256等。
该过程的计算资源强度可能是重复数据删除的缺点。为了提高性能,某些系统同时利用了弱散列和强散列。弱散列的计算速度要快得多,但是散列冲突的风险更大。利用弱散列的系统随后将计算强散列,并将其用作确定它是否实际上是相同数据的决定因素。请注意,与计算和查找哈希值相关的系统开销主要是重复数据删除工作流的功能。重组文件不需要此处理,并且与数据块的重新组装相关的任何增量性能损失都不太可能影响应用程序性能。
另一个问题是压缩和加密的交互。加密的目的是消除数据中任何可识别的模式。因此,即使基础数据可能是冗余的,也无法对加密的数据进行重复数据删除。
尽管这不是重复数据删除的缺点,但是当对重复数据删除数据的大型存储库使用不足的安全性和访问验证过程时,就会发生数据泄露。在一些系统中,如典型的与云存储,攻击者可以通过检索知道或猜测所期望的数据的哈希值由其他人所拥有的数据。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/106976/