
简介
编辑领域适应是一个与机器学习和迁移学习相关的领域。当我们旨在从源数据分布中学习一个在不同(但相关)目标数据分布上表现良好的模型时,就会出现这种情况。
例如,常见的垃圾邮件过滤问题的任务之一是将一个模型从一个用户(源分布)适应到一个收到明显不同的电子邮件的新用户(目标分布)。
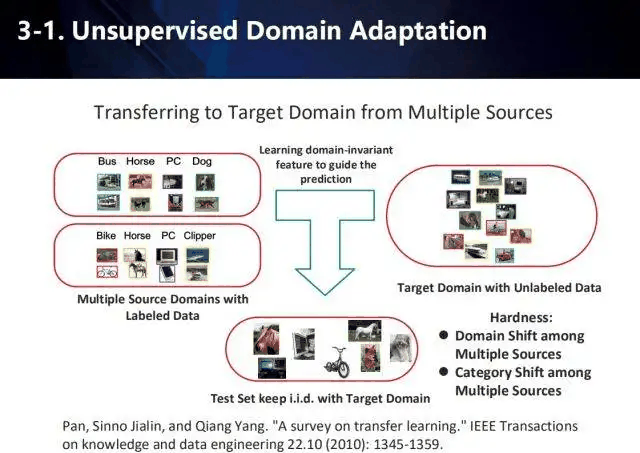
领域适应也被证明有利于学习不相关的来源。注意,当有一个以上的来源分布时,这个问题被称为多来源领域适应。
领域适应的概述
编辑领域适应是将在一个或多个源域中训练的算法应用于不同(但相关)的目标域的能力。
领域适应是迁移学习的一个子类别。
在领域适应中,源域和目标域都有相同的特征空间(但分布不同);相反,迁移学习包括目标域的特征空间与源特征空间不同的情况。
领域转移
编辑领域转移,或称分布性转移,是指算法的训练数据集与它在部署时遇到的数据集之间的数据分布变化。
这些领域转移在人工智能的实际应用中很常见。
传统的机器学习算法往往不能很好地适应领域的转变。现代机器学习界有许多不同的策略,试图获得更好的领域适应性。
领域适应的例子
编辑一个在新闻邮件上训练的算法可能必须适应新的生物医学文件数据集。一个垃圾邮件过滤器,在训练期间针对某组电子邮件用户进行训练,在部署时必须适应新的目标用户。其他应用包括wifi定位检测和计算机视觉的许多方面。
形式化
编辑让{dISPlaystyleX}是输入空间(或描述空间)。是输入空间(或描述空间),让{diSPlaystyleY}是输入空间(或描述空间),让Y是输出空间(或标签空间)。
机器学习算法的目标是学习一个数学模型(一个假说){displaystyleXtimesY}(未知且固定)。(未知和固定)。然后,我们的目标是学习{displaystyleS}中),使其对来自分布的新例子的标记误差最小。),从而使它在给来自分布的新例子贴标签时犯的错误最小。
监督学习和领域适应之间的主要区别在于,在后者的情况下,我们研究两个不同(但相关)的分布{displaystyleh}(从来自两个领域的有标签或无标签样本中学习)(从来自两个领域的有标签或无标签的样本中),使其在目标领域中的错误尽可能小。
领域适应的不同类型
编辑领域适应有几种情况。它们在考虑目标任务的信息方面有所不同。
无监督领域适应:学习样本包含一组有标签的源样本、一组无标签的源样本和一组无标签的目标样本。
半监督领域适应:在这种情况下,我们也考虑一小部分有标签的目标样本。
监督领域适应:所有考虑的样本都应该是有标签的。
四种算法原则重权算法目标是重权源标签样本,使其看起来像目标样本(就考虑的误差尺度而言)。
迭代算法
编辑适应的方法包括对目标样本进行迭代式的自动标记。其原理很简单。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/175584/