数据集成
编辑数据集合涉及组合驻留在不同来源的数据并为用户提供统一的视图。 这个过程在各种情况下变得很重要,包括商业(例如当两个类似的公司需要合并他们的数据库时)和科学(例如,结合来自不同生物信息学存储库的研究结果)领域。 随着数据量(即大数据)和共享现有数据的需求激增,数据集合的出现频率越来越高。 它已成为广泛理论工作的焦点,许多悬而未决的问题仍未解决。 数据集成鼓励内部和外部用户之间的协作。 被集成的数据必须从异构数据库系统接收,并转换为单一一致的数据存储,跨文件网络为客户提供同步数据。 数据集成的一个常见用途是在数据挖掘中分析和从现有数据库中提取对业务信息有用的信息。
历史
编辑合并异构数据源的问题通常被称为信息孤岛,在单一查询界面下已经存在了一段时间。 20 世纪 80 年代初,计算机科学家开始设计异构数据库互操作性系统。 xxx个由结构化元数据驱动的数据集成系统于 1991 年在明尼苏达大学设计,用于集成公用微数据系列 (IPUMS)。 IPUMS 使用数据仓库方法,从异构源中提取、转换和加载数据到一个独特的视图模式中,从而使来自不同源的数据变得兼容。 通过使数以千计的人口数据库具有互操作性,IPUMS 证明了大规模数据集成的可行性。 数据仓库方法提供了一种紧密耦合的架构,因为数据已经在一个可查询的存储库中进行了物理协调,因此通常只需很少的时间来解决查询。
数据仓库方法对于频繁更新的数据集不太可行,需要不断重新执行提取、转换、加载 (ETL) 过程以实现同步。 当一个人只有一个汇总数据源的查询接口而无法访问完整数据时,构建数据仓库也会遇到困难。 当集成多个商业查询服务(如旅游或分类广告 Web 应用程序)时,这个问题经常出现。
截至 2009 年,数据集成的趋势有利于数据的松散耦合,并提供统一的查询接口以通过中介模式访问实时数据(参见图 2),这允许直接从原始数据库中检索信息。 这与那个时代流行的SOA方式是一致的。 这种方法依赖于中介模式和原始源模式之间的映射,并将查询转换为分解查询以匹配原始数据库的模式。 这种映射可以用两种方式指定:作为从中介模式中的实体到原始源中的实体的映射(全局视图(GAV)方法),或者作为从原始源中的实体到中介模式中的映射 模式(本地即视图(LAV)方法)。 后一种方法需要更复杂的推理来解决对中介模式的查询,但可以更轻松地将新数据源添加到(稳定的)中介模式。
截至 2010 年,一些数据集成研究工作涉及语义集成问题。 这个问题解决的不是集成架构的结构,而是如何解决异构数据源之间的语义冲突。 例如,如果两家公司合并了他们的数据库,那么他们各自模式中的某些概念和定义(如收益)不可避免地具有不同的含义。 在一个数据库中,它可能表示以美元为单位的利润(浮点数),而在另一个数据库中,它可能表示销售额(整数)。 解决此类问题的常见策略涉及使用本体论,它明确定义模式术语,从而有助于解决语义冲突。 这种方法代表基于本体的数据集成。
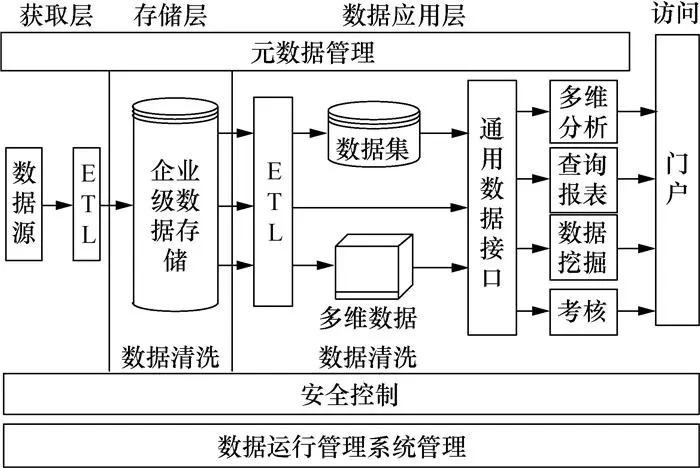

另一方面,结合来自不同生物信息学知识库的研究结果的问题需要根据单一标准(例如阳性预测值)对从不同数据源计算的相似性进行基准测试。 这使得数据源可以直接比较,并且即使在实验性质不同的情况下也可以进行整合。
截至 2011 年,已确定当前的数据建模方法正在以不同数据岛和信息孤岛的形式将数据隔离到每个数据架构中。 这种数据隔离是数据建模方法的意外产物,它会导致开发不同的数据模型。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/197029/