
什么是过度拟合
编辑在统计中,过度拟合是“过于紧密或精确地对应于特定数据集的分析结果,因此可能无法拟合其他数据或可靠地预测未来的观察结果”。一种过度拟合模型是一个统计模型包含多个参数比可以由数据是合理的。过度拟合的本质是在不知不觉中提取了一些残余变化(即噪声),好像该变化代表了基础模型结构一样。
换句话说,该模型记住了大量示例,而不是学习注意特征。
当统计模型无法充分捕获数据的基础结构时,就会发生欠拟合。一个欠拟合模型就是将出现在正确指定的模型某些参数或术语缺少的典范。例如,当将线性模型拟合到非线性数据时,会发生拟合不足。这样的模型往往具有较差的预测性能。
特别是在机器学习中,过度拟合和欠拟合可能会发生。在机器学习中,这种现象有时称为“过度训练”和“训练不足”。
存在过度拟合的可能性,因为用于选择模型的标准与用于判断模型的适用性的标准不同。例如,可以通过最大化模型在某些训练数据集上的性能来选择模型,但是其适用性可能取决于它在看不见的数据上表现良好的能力;然后,当模型开始“记忆”训练数据而不是“学习”从趋势进行概括时,就会发生过度拟合。
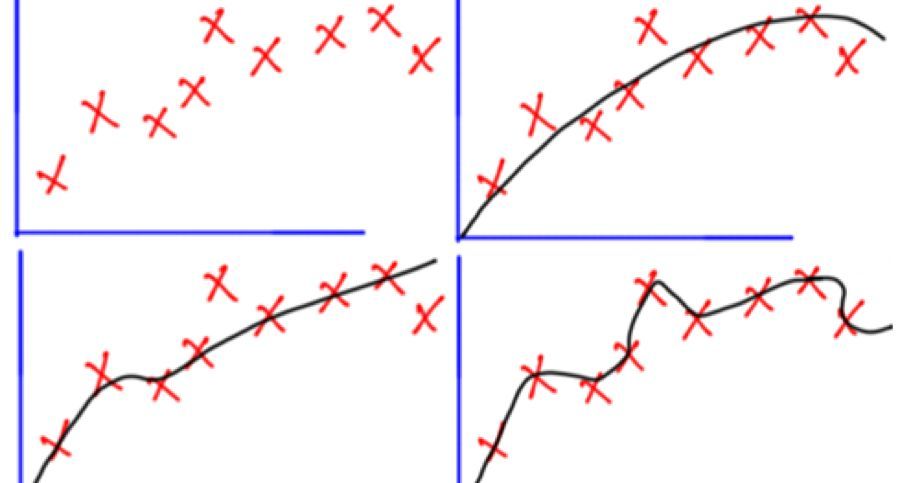
作为一个极端的例子,如果参数的数量等于或大于观察值的数量,则模型可以简单地通过完整地记住数据来完美地预测训练数据。但是,这样的模型在进行预测时通常会严重失效。
过度拟合的可能性不仅取决于参数和数据的数量,还取决于模型结构与数据形状的一致性,以及与预期的噪声或数据误差水平相比模型误差的大小。即使拟合模型没有过多的参数,也可以预期,拟合关系在新数据集上的表现将比在拟合数据集上的表现差(有时会出现这种现象称为收缩)。特别地,确定系数的值将相对于原始数据缩小。
为了减少过度拟合的机会或过度拟合的数量,可以使用几种技术(例如,模型比较、交叉验证、正则化、提早停止、修剪、贝叶斯先验或辍学)。
一些技术的基础是(1)显式惩罚过于复杂的模型,或者(2)通过在未用于训练的一组数据上评估其性能来测试模型的概括能力,假定该数据近似于典型的看不见的数据模型会遇到的问题。
统计推断
编辑在统计中,从统计模型中得出推论,该模型已通过某种过程选择。伯纳姆&安德森(Burnham&ANDerson)在其关于模型选择的引文中认为,为避免过度拟合,我们应坚持“简约原则”。作者还声明以下内容。
过度拟合的模型…通常在参数估计器中没有偏差,但是估计(和实际)的采样方差不必要地很大(相对于使用更简化的模型可以实现的估计量、估计器的精度很差)。往往会发现错误的处理效果,并且过拟合模型中包含错误的变量。…通过适当地平衡欠拟合和过拟合的误差,可以获得最佳的近似模型。
当几乎没有可用的理论来指导分析时,过度拟合可能会成为一个严重的问题,部分原因是因为那时倾向于从大量模型中进行选择。《模型选择和模型平均》(2008)一书就是这样写的。
有了一个数据集,您只需按一下按钮就可以适应数千个模型,但是如何选择最佳模型呢?对于这么多候选模型,过度拟合是一个真正的危险。打哈姆雷特的猴子真的是个好作家吗?
回归
编辑在回归分析中,过度拟合经常发生。作为一个极端的例子,如果有p的变量中一个线性回归用p个数据点,所述拟合线可以去精确地通过每一个点。对于logistic回归或Cox比例风险模型,有多种经验法则(例如5–9 、10和10–15—每个独立变量10次观察的准则是被称为“十分之一的规则”)。在选择回归模型的过程中,可以将随机回归函数的均方误差分解为随机噪声,近似偏差和回归函数估计中的方差。偏差-方差折衷通常用于克服过拟合模型。
使用大量实际上与预测的因变量无关的解释变量,通常会错误地发现某些变量具有统计意义,因此研究人员可能会将其保留在模型中,从而使模型过拟合。这就是所谓的弗里德曼悖论。
机器学习
编辑通常,使用一组“训练数据”来训练学习算法:已知输出的示例性情况。目的是当算法在训练期间未遇到的“验证数据”被馈入时,该算法在预测输出时也将表现良好。
过度拟合是指使用违反Occam剃刀的模型或程序,例如,通过包含比最终最优的参数更多的可调整参数,或通过使用比最终最优的更为复杂的方法。对于可调参数太多的示例,请考虑一个数据集,其中可以通过两个独立变量的线性函数充分预测y的训练数据。这样的函数仅需要三个参数(截距和两个斜率)。用一个新的,更复杂的二次函数或一个新的,更复杂的线性函数替换两个以上的自变量来替换此简单函数会带来风险:Occam的剃刀意味着任何给定的复杂函数都是先验的比任何给定的简单函数都不太可能。如果选择新的,更复杂的功能而不是简单的功能,并且如果训练数据拟合中没有足够大的增益来抵消复杂性的增加,则新的复杂函数将“过度拟合”数据,而复杂的则过度拟合函数对训练数据集外部的验证数据的性能可能会比简单函数差,即使复杂的功能在训练数据集上也表现得更好甚至更好。
在比较不同类型的模型时,不能仅通过计算每个模型中存在多少参数来衡量复杂性。还必须考虑每个参数的表达能力。例如,将具有m个参数的神经网络(可以跟踪曲线关系)直接与具有n个参数的回归模型进行比较是很重要的。
在学习时间过长或训练实例很少的情况下,过度拟合尤其可能导致学习者适应训练数据的非常具体的随机特征,而这些随机特征与目标功能没有因果关系。在过度拟合的过程中,训练示例的性能仍然会提高,而看不见数据的性能会变得更差。
作为一个简单的示例,请考虑零售购买的数据库,其中包括购买的商品,购买者以及购买日期和时间。通过使用购买日期和时间来预测其他属性,可以很容易地构建一个完全适合训练集的模型,但是该模型根本不会推广到新数据,因为过去的时间将不再发生。
通常,如果一种学习算法在拟合已知数据时更准确(事后知会),而在预测新数据时则不那么准确(事后预测),则相对于一种更简单的学习算法来说过拟合。一个人可以从以下事实中直观地了解过度拟合的事实:过去的所有经验信息可以分为两类:与未来相关的信息和不相关的信息(“噪声”)。在其他所有条件都相同的情况下,准则越难以预测(即不确定性越高),过去的信息中存在的噪声越多,需要忽略。问题在于确定要忽略的部分。可以减少拟合噪声的机会的学习算法称为“健壮”。
后果
编辑过度拟合的最明显结果是验证数据集的性能不佳。其他负面后果包括:
- 与最佳函数相比,过度拟合的函数可能会请求有关验证数据集中每个项目的更多信息;收集这些额外的不需要的数据可能是昂贵的或容易出错的,特别是如果必须通过人工观察和手动数据输入来收集每条单独的信息的话。
- 比起简单的功能,更复杂,过度拟合的功能可能不太容易移植。在一个极端情况下,单变量线性回归非常方便,以至于必要时甚至可以手动完成。在另一个极端是只能通过完全复制原始建模者的整个设置才能复制模型,从而使重用或科学复制变得困难。
补救措施
编辑最佳功能通常需要在更大或全新的数据集上进行验证。但是,有一些方法,例如最小生成树或相关性的生存时间,它们会应用相关系数和时间序列(窗口宽度)之间的相关性。只要窗口宽度足够大,相关系数就会稳定,不再依赖于窗口宽度大小。因此,可以通过计算研究变量之间的相关系数来创建相关矩阵。该矩阵可以在拓扑上表示为复杂的网络,其中可以直观显示变量之间的直接和间接影响。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/114919/