
生成式人工智能(Generative Artificial Intelligence)是一种能够根据提示生成文本、图像或其他媒体信息的人工智能。其原理在于利用机器学习技术在现有的大规模多模态数据集基础上生成新的文本、程序代码、图像、视频和声音等数据,具备处理多种任务和场景的能力。
发展历程
编辑早期发展阶段(1950s-1990s)
在AIGC的早期阶段,由于科技水平的限制,进行了小范围实验。1957年,希勒和艾萨克森通过将计算机程序中的控制变量转换成音符,创作了历史上第一支由计算机创作的音乐作品《依利亚克组曲》。1966年,魏岑鲍姆和科尔比合作开发了世界上第一款可进行人机对话的机器人“伊莉莎”,该机器人通过关键字扫描和重组完成交互任务。80年代中期,IBM基于HMM模型创造了语音控制打字机“坦戈拉”,能处理约20000个单词。然而,由于高昂的系统成本,80年代末至90年代中期各国政府减少了在人工智能领域的投入,导致AIGC未能取得重大突破。
沉淀积累阶段(1990s-2010s)
AIGC逐渐从实验性发展向实用性演变。2006年,深度学习算法取得重大突破,同时GPU、TPU等算力设备性能提升,互联网为各类人工智能算法提供海量训练数据,推动了人工智能的显著进步。然而,AIGC仍然面临算法瓶颈,限制了其在创作任务上的表现,应用范围有限,效果有待提升。2007年,纽约大学的罗斯·古德温装配的人工智能系统创作了小说《1 The Road》,这是世界上第一部完全由人工智能创作的小说。2012年,微软展示了一个基于深层神经网络的全自动同声传译系统,能够通过语音识别、语言翻译、语音合成等技术将英文演讲者的内容自动转换成中文语音。这标志着AIGC在语音处理领域取得了一些进展。
快速发展阶段 (21 世纪 10 年代中期至今)
自2014年起,随着深度学习算法的发展,特别是生成式对抗网络(GAN)的提出和不断迭代,AIGC进入了新的时代。生成内容呈现多样化,逼真程度逐渐提高,甚至达到了人类难以分辨的水平。2017年,微软推出了人工智能少女“小冰”,发布了世界上首部由100%人工智能创作的诗集《阳光失了玻璃窗》。2018年,英伟达发布了StyleGAN模型,该模型能够自动生成逼真的图片,目前已经升级到第四代模型StyleGAN-XL。2019年,DeepMind发布了DVD-GAN模型,用于生成连续视频。2021年,OpenAI推出了DALL-E,并于一年后推出了升级版本DALL-E-2,主要用于文本与图像的交互生成内容。用户只需输入简短的描述性文字,DALL-E-2即可创作出卡通、写实、抽象等风格的绘画作品。2022年底,OpenAI推出了ChatGPT,其全称是生成式预训转换机器人,是一款模仿自然语言的应用,该应用的特点是,利用神经网络架构并接受大量数据和语料库的机器学习,能够模仿普通人的对话和写作。2023年3月16日,微软宣布引入名为Copilot的人工智能服务,并将其整合到Word、PowerPoint、Excel等Office办公软件中。该服务具备根据各软件的功能和需求处理不同类型任务的能力。这些进展标志着AIGC在生成内容方面取得了显著的突破。2024年7月3日,世界知识产权组织发布《生成式人工智能专利态势报告》。报告显示,2014年至2023年,中国发明人申请的生成式人工智能专利数量最多,远超美国、韩国、日本和印度等国。2014年至2023年,全球生成式人工智能相关的发明申请量达54000件,其中超过25%是在2023年一年出现的。
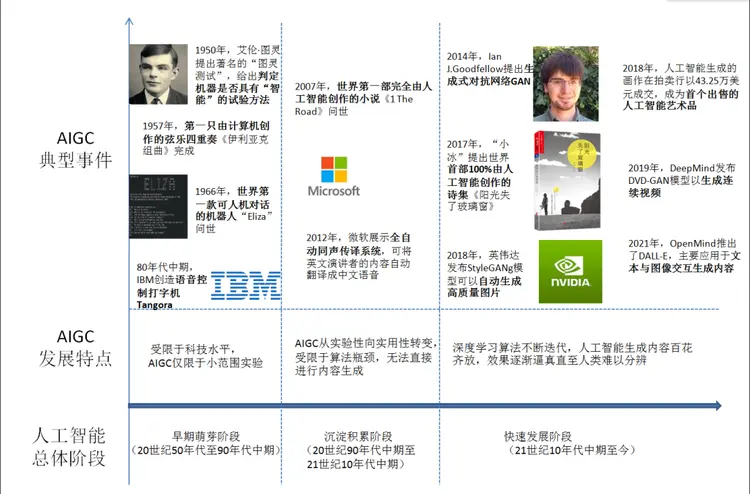 AIGC发展历程
AIGC发展历程
特点
编辑涌现能力
AIGC通过创造性再创作,使得模型在足够大和建模能力足够强的情况下,能够具备自然语言理解的推理能力。常识推理一直是人工智能领域的重大难题,LLM 的出现加上算力成本的降低使常识推理取得了重大进展,通过思维链提示能够解决复杂推理难题。
基础承载能力
AIGC在生成式对抗网络和Transformer等生成算法的支持下,通过海量无监督预训练降低了对标注数据的依赖,利用未标注数据自主学习规律,并通过微调在特定任务上提升模型能力,实现了在多领域任务上的统一建设。
自然语言交互
AIGC爆发的标志是基于自然语言交互的ChatGPT等平台的涌现,使得AIGC不仅适用于专业人员,还包括普通民众。用户对社交软件自然语言交互的熟悉和喜好推动了AIGC的广泛应用,但也引入了全方位的数据和数据安全风险。
类型
编辑根据内容生产的不同模态,AIGC可划分为四个基础模态,分别涵盖文本、音频、图像和视频。每一种模态技术都具有独特的应用场景和特性。此外,这四种模态的融合产生了第五种模态——跨模态内容生成模式,使AIGC能够创造更加丰富多样的生成内容。
文本
文本内容生成主要可划分为两大类:非交互式和交互式。在非交互式文本生成方面,包括了摘要/标题生成、文本风格迁移、文章生成以及图像生成文本等技术。这些方法能够根据具体的应用场景,自动生成满足要求的文本内容,从而提高生成效率和内容质量。而在交互式文本生成方面,更为智能化的应用方式允许根据用户的需求和反馈,生成更贴近用户期望的内容。这一类应用主要包括聊天机器人、文本交互游戏等。文本内容生成方面的代表性产品或模型包括JaSPerAI、copy.AI、ChatGPT、Bard、AI dungeon等。
 JasperAI
JasperAI
音频
音频生成技术是一种使用算法和模型生成人工音频的技术。这种技术一般在特定场景下应用,例如文本转语音,如数字人的播报、语音客服等。在这些场景中,通过算法生成符合用户和场景需求的语音,从而提升用户体验和操作效率。此外,这一技术在各种C端产品中广泛应用,包括智能家居、车载音响、虚拟助手等。音频生成方面的代表性产品或模型包括DeepMusic、WaveNet、Deep Voice、MusicAutoBot等。
 DeepMusic.AI
DeepMusic.AI
图像
图像生成技术是一种利用算法和模型生成人工图像的先进技术。可根据应用场景分为图像编辑修改和图像自主生成两大类。图像编辑修改技术致力于对图像进行重构和修复,提升图像的质量和清晰度,以满足用户对图像处理的多样需求,包括图像修复、人脸替换、图像去水印等方面。而图像自主生成技术则通过算法和模型实现对图像的全新生成,为用户提供更为多样化的图像服务,例如参照图像生成绘画图像、真实图像生成素描图像、文本生成图像等。图像生成方面的代表性产品或模型包括EditGAN,Deepfake,DALL-E、MidJourney、Stable Diffusion,文心一格等。
 EditGAN效果示意图
EditGAN效果示意图
视频
视频生成技术是一种利用算法和模型生成人工视频的先进技术。该技术根据应用场景分为视频编辑和视频自主生成两大类。视频编辑技术广泛应用于视频超分辨率、视频修复、视频画面剪辑等方面。而视频自主生成技术的核心原理是通过深度学习模型对图像或视频进行分析和理解,然后根据特定算法生成相应的视频。这一技术可以应用于图像生成视频、文本生成视频等多个领域。视频生成方面的代表性产品或模型包括Deepfake,videoGPT,Gliacloud、make-A-Video、Imagen video。
 Gliacloud
Gliacloud
跨模态
跨模态生成是指通过结合不同模态的AI技术,实现模态之间的转换和生成。这一技术通过在不同媒介之间进行转化和生成,拓展了人工智能应用的领域和应用场景,它支持将不同的信息形式转化为人类可理解的其他形式。例如,将文本转化为图像、音频或视频,将图像转化为文本、音频或视频,从而实现更为自然、直观和高效的交互方式。跨模态生成技术同时也可以广泛应用于艺术创作、广告营销、教育培训、医疗诊断等多个领域,提升AIGC的产业化和工业化应用能力。跨模态生成方面的代表性产品或模型包括DALL-E、MidJourney、Stable Diffusion。

MidJourney
技术细节
编辑概率生成模型
概率生成模型是一种统计模型,它可以学习观察数据的联合概率分布。在生成模型中,我们努力找到在给定输入特征的情况下,期望输出或标签同时存在的联合概率。生成模型通常被用于估计概率和可能性,通过这些概率对数据点进行建模,并基于这些概率进行分类。由于该模型学习了数据集的概率分布,因此它能够参考这一分布来生成新的数据实例。生成式人工智能的核心在于概率生成模型,这些模型致力于学习输入数据的概率分布。一旦模型完成训练,便可从该分布中进行抽样,生成新的数据。常见的概率生成模型包括自回归模型、生成式对抗模型、变分自编码模型、流模型和扩散模型。
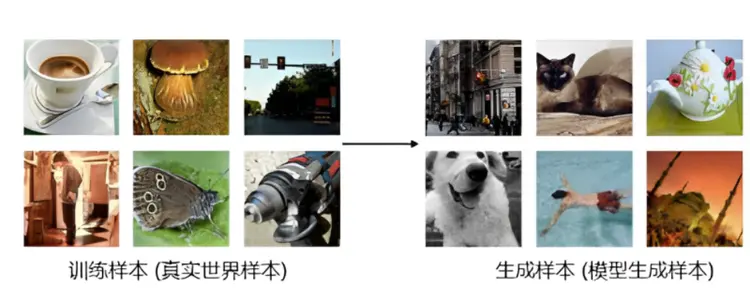 概率生成模型样例
概率生成模型样例
对抗学习机制
对抗学习是一种机器学习方法,它通过让两个网络相互竞争对抗的方式进行学习。这种学习机制通常包括两个关键角色:生成器和判别器。生成器的任务是生成尽可能真实的数据,而判别器的任务是区分生成的数据和真实的数据。生成器通过不断学习训练库中真实图片的概率分布,将输入的随机噪声转变为新的图片样本(即假数据),使得生成数据的分布尽可能逼近真实数据的分布。判别器同时观测真实和虚构的数据,致力于判别输入数据的真实性。通过反复的交替训练和对抗,生成器和判别器的能力将不断增强,直至达到一种均衡状态。最终训练完成的生成器能够生成高质量、以假乱真的图片。这种对抗学习机制在深度学习中得到广泛应用,特别是在生成对抗网络(GAN)中。
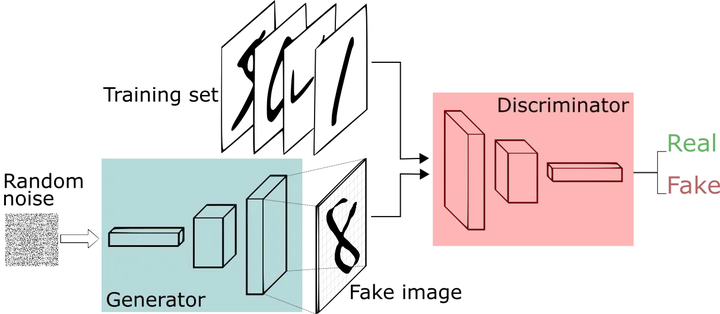 GAN基本结构
GAN基本结构

生成对抗网络的重要部分
潜在变量建模
潜在变量模型是一种统计模型,其将一组可观察变量(也被称为显变量或指标)与一组潜在变量相关联。在许多生成模型中,潜在变量被引入以捕捉输入数据的内在结构。例如,在变分自编码器中,潜在变量用于表示输入数据的压缩表征,然后通过解码从这一表征中重构原始数据。
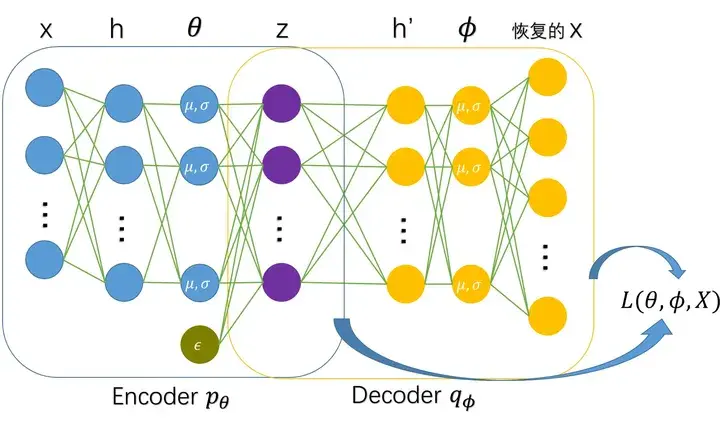 变分自编码器的网络结构
变分自编码器的网络结构
深度神经网络
深度神经网络是一种具有一定复杂性的神经网络,它是一个包含多于两层的神经网络。深度神经网络使用复杂的数学建模来以复杂的方式处理数据。同时深度神经网络是一种机器学习类型,模仿大脑学习的方式。它已经被用于各种任务,包括语言翻译、图像搜索工具,甚至医学诊断。生成式人工智能使用一种称为生成对抗网络(GANs)的深度学习来创建新的内容。
对抗训练策略
对抗训练策略是一种用于提高机器学习模型对抗攻击鲁棒性的防御方法。该策略通过在对抗性和干净示例的混合数据集上进行模型训练,从而增强模型对攻击的鲁棒性。对抗训练是提高深度学习模型对对抗示例抵御能力的最为有效的方法之一。与其他防御策略不同,对抗训练主要加强模型的内在鲁棒性。对抗训练策略广泛应用于生成对抗网络(GANs)的训练中。生成对抗网络的成功训练方法确保目标函数收敛到局部最小值。此外,对抗攻击是一种故意试图通过提供欺骗性输入来混淆机器学习模型的尝试。生成对抗性示例是最常见的对抗攻击类型,攻击者有意设计这些输入以导致模型出错。
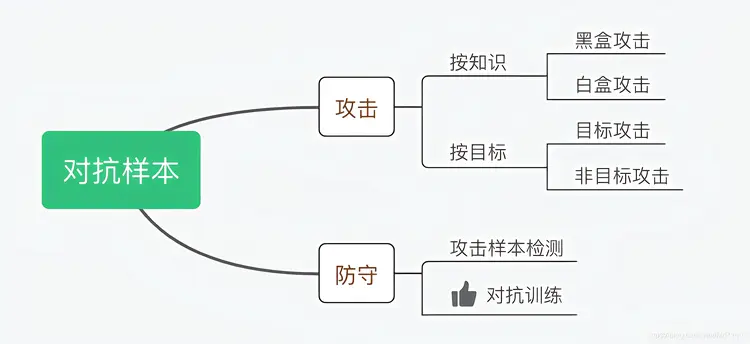
对抗训练方式分类
应用实例
编辑ChatGPT
ChatGPT是OpenAI开发的人工智能聊天机器人,允许用户通过书面提示与其交互,生成类人文本的回应。OpenAI成立于2015年,由Elon Musk和Sam Altman创立,并得到微软等知名投资者支持。ChatGPT属于生成式人工智能,该服务以文本为基础,能够对用户请求产生类似人类的回应,如生成诗歌或提供建议。ChatGPT的独特之处在于由大型语言模型GPT-3.5支持,该模型是GPT-3的升级版,拥有1750亿个参数,是迄今为止最大、最强大的语言处理AI模型之一。ChatGPT能理解人类语言并生成类似人类反应的文本,表现出令人印象深刻的人性化响应。其另一个特点是能够记录上下文,提高对话的连贯性,这一能力使得ChatGPT在交流中更具人性化。
 ChatGPT使用示意图
ChatGPT使用示意图
DALL-E
DALL·E是一款人工智能系统,以自然语言描述为基础,具备创造逼真图像和艺术的能力。其特色在于图像生成,能够创作原创逼真的图像和艺术作品,以及构图扩展,通过将图像扩展到原始画布之外,创造全新的构图。此外,DALL·E还支持实时编辑,通过自然语言字幕对现有图像进行真实编辑,以及图像变体,能够生成原始图像的不同变体,为用户提供更多选择。在2021年1月推出DALL·E后,一年后推出了更新版本DALL·E 2,生成更逼真、更准确的图像,分辨率提高了4倍。在2023年10月初,OpenAI向ChatGPT Plus和Enterprise客户提供了DALL·E 3,具有更好的效果和更强的安全性。DALL·E 3还可以与ChatGPT联动,当用户提出想法时,ChatGPT将自动生成定制的详细提示,将用户的想法转化为现实。
 DALL-E示意图
DALL-E示意图
DeepFake
Deepfake是一种人工智能人像生成技术,涵盖面部替换、面部重演和人脸生成等方面。通过面部替换,该技术能够将人像巧妙地合成到已有的图片或视频中,达到逼真的效果。在面部重演方面,Deepfake可以操纵视频中的人像面部特征,包括口型、眉毛、眼睛运动和头部倾斜,从而改变其表情。同时,通过基于训练数据的人脸生成,Deepfake能够创造出全新的人脸图像,扩展了其应用领域。这一技术的发源可追溯至2017年,最初由Reddit用户“deepfakes”在该平台发布名人换脸视频而得名。深度伪造主要基于生成对抗网络(GAN),这种深度学习模型通过两个相互对抗的神经网络,一个用于生成图像,另一个用于判别输出是否真实,通过交替优化训练,生成的深度伪造内容足以逼真地欺骗人的视觉。在Deepfake技术的应用中,换脸是最常见的,它涉及交换两个人的脸;人脸合成则用于生成从未存在过的人的面孔;而在面部属性和表情操纵中,通过改变特定特征如眼睛、眉毛等,可以调整面部的表情。整个过程的关键在于将一个人的解码器应用于另一个人的潜在面孔,实现输出人脸具有一个人的表情和结构,同时保留另一个人的风格和神情。

DeepFake实例
DeepDream
DeepDream是由谷歌于2015年发布的一种图像生成算法,可以将神经网络学习模式可视化展现。 DeepDream的原理是通过输入一张图像到一个卷积神经网络,让网络告诉我们这张图像可能包含哪些物体。我们可以选择一个目标,比如海星,然后通过调整输入图像的像素值,使得网络认为图像里有海星。这个过程中,我们不是调整神经网络的规则,而是在图像上操作,使它看起来更像目标。这种方法不仅可以生成有趣的图像,还能揭示神经网络内部学到的信息。类似孩子们观察云朵并试图解释随机形状,DeepDream 过度解释并增强图像中存在的图案,从而强化网络对特定图案的识别能力,生成梦幻般的图像。
 DeepDream实例
DeepDream实例
MuseNet
MuseNet是使用Sparse Transformer技术的音乐生成系统,可根据输入的音符组预测下一个音符。模型由72层网络和24个注意力头组成,训练数据包括ClassicalArchives、BitMidi等来源的MIDI文件。MuseNet支持以10种乐器创作4分钟的音乐,模仿不同作曲家的风格,同时具备融合多种音乐风格的能力。它的原型提供简单和高级模式,用户可在高级模式下与模型交互生成全新音乐作品。
 MuseNet页面
MuseNet页面
相关争议
编辑技术和安全风险
基于算法能力的内容安全风险:
- 生成式人工智能改变了信息生成和传播模式,使得虚假信息泛滥成为可能。
- 应用如ChatGPT可操纵用户情绪、传播虚假信息,危害社会稳定和国家安全。
- 偏见性数据导入和算法建构可能导致内容生成具有偏见的意识形态输出。
基于技术应用的数据安全风险:
- 人工智能训练数据安全问题,包括数据违规获取、合成数据不当使用、歧视性标注和敏感数据存储安全。
- 大规模数据集中包含大量敏感数据,可能引发隐私和跨境数据流动问题。
基于大模型的算法安全风险:
- 大模型引发的算法透明度低,使得算法运行过程难以监控,加剧信息不对称。
- 复杂的内部工作机制导致生成式人工智能模型解释性困难,增加了算法归责的难度。
- 训练数据的偏差可能导致模型在某些领域的预测结果出现偏差,影响算法的公平性和准确性。
国际态度
生成式人工智能的发展和应用,引起了国际社会的高度关注和重视,各国和国际组织纷纷采取措施,加强对生成式人工智能的监管和治理,以确保其安全、可靠、可信、可控。
中国
2021年9月25日,国家新一代人工智能治理专业委员会发布《新一代人工智能伦理规范》。该规范旨在将伦理道德融入人工智能全生命周期,为从事相关活动的个人、法人和机构提供伦理指引。规范包括总则、特定活动伦理规范和组织实施,提出了六项基本伦理要求,如增进人类福祉、促进公平公正等,以及18项特定活动的伦理要求。该规范的发布旨在引导负责任的人工智能研发和应用,促进健康发展。2023年5月23日,中国国家互联网信息办公室发布了《生成式人工智能服务管理暂行办法》,旨在规范技术发展、服务规范和监管措施。强调鼓励技术创新,提供者需遵守法规,防范违法内容,明确服务适用范围,保护用户隐私。监管部门将加强管理,对具有社会动员能力的服务进行安全评估。违规行为将面临行政处罚和法律责任。该办法自2023年8月15日起正式生效。
美国
2017年,美国众议院发布《人工智能创新团队法案》,2018年发布《人工智能就业法案》,旨在应对人工智能对就业的挑战,倡导创造终身学习和技能培训环境。同年,美国设立人工智能国家安全委员会,负责审查AI技术在军事应用中的风险,处理AI技术在国家安全和国防领域的伦理道德问题,并推动公开训练数据标准和共享。2019年,美国国防创新委员会发布《人工智能原则:国防部人工智能应用伦理的若干建议》,明确了“负责、公平、可追踪、可靠、可控”等五大必须遵守的原则。2020年10月,美国白宫发布了《人工智能权利法案蓝图》,列出了五项原则,以“指导自动化系统的设计、使用和部署,保护人工智能时代的美国民众。
欧洲各国
2021年4月21日,欧盟提出《人工智能法案》的草案,旨在为人工智能治理提供具有法律约束力的支持。该法案以风险预防为基础,制定了全面的规定体系,以推动创新,将欧洲建设成为可信赖的全球人工智能中心。截至2022年12月6日,欧盟理事会通过了关于该法案的共同立场,以确保在欧盟市场投放和使用的人工智能系统的安全性,并遵守现行法律。2023年3月,该法案提交欧盟议会进行初审,4月27日,欧洲议会成员就《人工智能法案》达成了临时政治协议,要求生成式人工智能公司透露用于开发系统的受版权保护的材料。此协议为《人工智能法案》的通过铺平了道路。2023年6月14日,欧洲议会投票通过了《人工智能法案》,明确了禁止实时面部识别以及ChatGPT等生成式人工智能工具的规定。该法案将进入欧盟委员会、议会和成员国的三方谈判协商程序,以确定最终版本。作为全球首个综合性人工智能治理法案,它将成为全球人工智能法规的标杆,为各国监管机构提供广泛的参考。此外,还有一些国际组织和学者,呼吁对生成式人工智能进行更严格的限制和禁止,以防止其对人类社会造成不可逆转的危害。
内容由匿名用户提供,本内容不代表vibaike.com立场,内容投诉举报请联系vibaike.com客服。如若转载,请注明出处:https://vibaike.com/1230774/